¶ Les bases
¶ Fichier de configuration
- Le fichier de configuration de Prometheus est écrit en YAML
La configuration de Prometheus comprend plusieurs sections différentes, telles que global, job_name, scrape_configs et rule_files.
-
globalcontient des configurations qui s'appliquent en général à l'ensemble de Prometheus.
Il y a deux configurations importantes dans cette sectio :scrape_interval: fréquence à laquelle Prometheus récupère les donnéesevaluation_interval: réévalue les règles (alertes).scrape_timeoutqui détermine le temps d'attente maximal lors du scraping.
-
job_namecontient des configurations spécifiques pour un bloc spécifique de Prometheus, comme le nom de ce bloc. Il y a également une configurationmetrics_pathqui détermine la route utilisée pour le scraping des métriques, et une configurationstatic_configqui contient des informations supplémentaires telles que les labels utilisés pour standardiser les données et les cibles (URL/IP:ports) pour le scraping. -
La section
scrape_configscontient des configurations spécifiques pour le scraping. Il y a une configurationjob_namequi détermine le nom de ce bloc de scraping, et une configurationmetrics_pathqui détermine la route utilisée pour récupérer les métriques. Il y a également une configurationstatic_configqui contient des informations supplémentaires telles que les labels utilisés pour standardiser les données et les cibles (URL/IP:ports) pour le scraping. -
rule_filescontient les configurations des alertes utilisées par Prometheus, y compris les fichiers de règles utilisés pour définir les alertes.
Voici un exemple de configuration prometheus.yaml :
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_timeout: 10s
scrape_configs:
- job_name: "example_app"
metrics_path: "/metrics"
static_configs:
- targets: ["host1:9090", "host2:9090"]
rule_files:
- "/path/to/rules.yaml"
Dans cet exemple, Prometheus est configuré pour récupérer les données toutes les 15 secondes et pour réévaluer les règles toutes les 15 secondes. Le temps d'attente maximal pour la récupération des données est de 10 secondes. Il y a un seul bloc de scraping nommé example_app qui utilise la route /metrics pour récupérer les métriques. Il y a deux cibles définies pour ce bloc de scraping host1:9090 et host2:9090. Enfin, il y a un fichier de règles /path/to/rules.yaml qui est utilisé pour les alertes.
¶ Définitions
Dans Prometheus, il existe deux principales définitions: les jobs et les instances.
- jobs : Un "job" est un groupe de cibles (URL/IP:ports) qui partagent une configuration de scraping commune. Les jobs sont identifiés par un nom unique, qui est utilisé pour regrouper les cibles de scraping.
- instances : Une "instance" est une cible spécifique (URL/IP:port) qui est récupérée par Prometheus. Les instances sont identifiées par un nom unique, qui est utilisé pour regrouper les métriques de cette cible.
Les métriques sont des valeurs numériques qui sont récupérées par Prometheus à partir des instances. Les métriques ont une structure de nom unique qui comprend un préfixe de l'application, suivi de plusieurs champs de labellisation optionnels qui décrivent la métrique.
Par exemple :
# up{job="<job-name>", instance="<instance-id>"} <value>
node_cpu_seconds_total{cpu="0",mode="iowait"} 0.3
process_cpu{instance="192.168.1.10:9100",job="node_exporter",service="myapp"} 42
Le nom d'une métrique est en général : <prefix_app>_<nom>_<unit>_<calcul>{<label>="<valeur>", ...} <valeur_metric>
Concernant le naming, la doc prometheus comporte beaucoup d'exemples : https://prometheus.io/docs/practices/naming/
¶ Interface Graphique
Depuis localhost:9090 nous pouvons directement faire des queries, par exemple :
- Récupérer la valeur d'une instance précise :
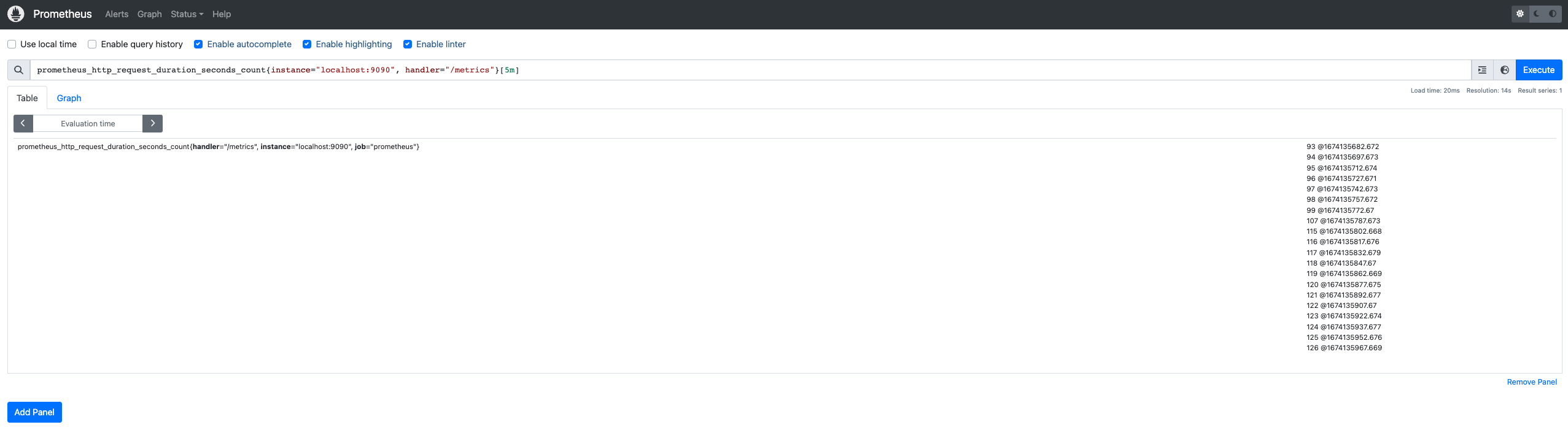
prometheus_http_request_duration_seconds_count{instance="localhost:9090", handler="/metrics"} - Récupérer la valeur d'une instance précise sur un lapse de temps donnés :
prometheus_http_request_duration_seconds_count{instance="localhost:9090", handler="/metrics"}[5m]
On peut aussi afficher le résultat via un graph :
- Query :
prometheus_http_request_duration_seconds_count{instance="localhost:9090", handler="/metrics"}
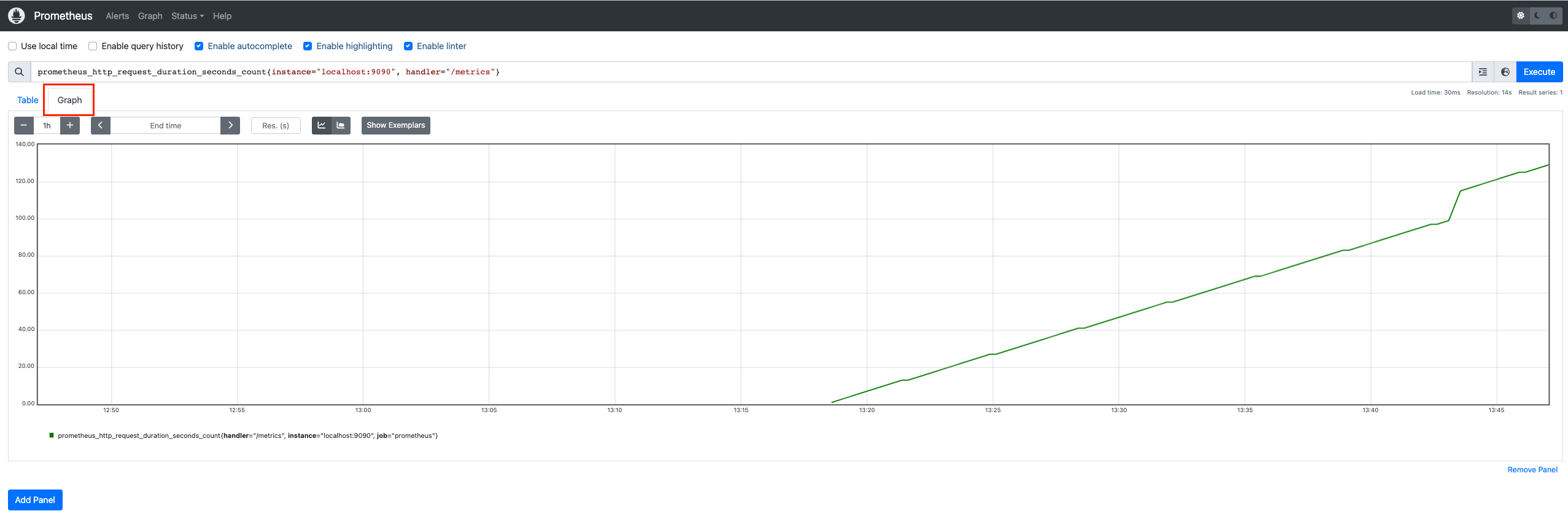
Globalement, l'interface prometheus peut servir à préparer les queries pour Grafana.