¶ Les fondamentaux k8s
Dans cette section nous allons voir les fondamentaux (container, pods, services...).
¶ Les containers et pods
Un pod est composé d'un ou plusieurs containers, volume(s) et d'une IP unique dans le réseau du cluster Kubernetes :
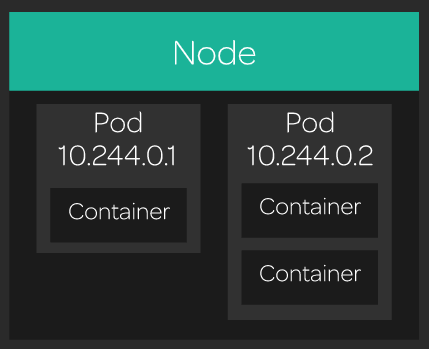
(source: LinuxAcademy)
Pour faire tourner les containers, kube-scheduler va envoyer l'information de faire tourner un pod avec X container(s) sur un noeud.
Nous allons créer un pod avec un container. Un serveur nginx, voici à quoi ressemble la configuration d'un pod (YAML) :
apiVersion: v1
kind: Pod # Type d'objet
metadata:
name: nginx # Nom du pod
spec:
containers:
- name: nginx # Nom
image: nginx # Image utilisée
On pourrait exécuter ce pod via la commande :
kubectl run nginx --image=nginx
Enregistrer ce fichier de configuration dans nginx.yml puis créer celui-ci :
kubectl create -f nginx.yml
Il est aussi possible d'appliquer la configuration de la manière suivante :
kubectl apply -f nginx.yml
apply va permettre de créer ou de mettre à jour le/les pods, ce que ne fait pas create.
Pour afficher la liste des pods :
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx 1/1 Running 0 11s
# Plus d'informations
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx 1/1 Running 0 5m22s 10.244.2.3 15634bebb11c.mylabserver.com <none> <none>
# Get pods de tous les namespaces
$ kubectl get pods --all-namespaces
Si on veut plus d'informations sur un pod en particulier :
kubectl describe pod nginx # Namespace par défaut (default)
kubectl describe pod nginx -n <namespace>
Pour supprimer un pod :
kubectl delete pod nginx
Ou alors via un fichier yaml :
kubectl delete -f nginx.yml
Révision des PODS :
- Un pod tourne TOUJOURS sur un noeud
- Un noeud est un “worker” dans un cluster kubernetes
- Chaque noeud est managé par le master
- Un noeud peut avoir plusieurs pods
¶ Cluster et noeud
Un cluster Kubernetes possède un ou plusieurs serveur de contrôle (Master : kube-apiserver, etcd, scheduler...) qui gère et contrôle le cluster. Ce type de noeud n'exécute pas de pods.
Afin d'afficher les noeuds du cluster :
$ kubectl get node
NAME STATUS ROLES AGE VERSION
node1 NotReady control-plane 5m24s v1.27.2
node2 NotReady <none> 6s v1.27.2
Si l'on veut plus de détails sur un noeud :
kubectl describe node node1
¶ Réseau
Il est important de connaitre le fonctionnement du réseau entre les pods, les services dans un cluster.
Kubernetes crée un réseau virtuel entre chaque noeud du cluster. Chaque pod sur le cluster à une IP unique et peut communiquer avec n'importe quel autre pod du cluster, même si celui-ci tourne sur un autre noeud.

(source: LinuxAcademy)
Kubernetes impose les bases suivantes :
- Les pods sur un noeud peuvent communiquer avec tous les pods sur TOUS les noeuds sans utiliser de NAT
- Tous les noeuds peuvent communiquer avec les pods sans utiliser de NAT
- L’IP que le pod voit est la même IP que les autres voient de lui
Kubernetes supporte différents plugins réseau qui implémente ça de façon différentes. Ici, nous utiliserons le plugin kube-router (il en existe de nombreux: Calico, Flannel, Weave...).
Il y a 4 challenges réseaux qui nécessitent d’être résolu :
- Réseau Container-to-Container
- Réseau Pod-to-Pod
- Réseau Pod-to-Service
- Réseau Internet-to-Service
¶ Container-to-Container
Container to container est essentiellement dans un pod.
Les PODs peuvent contenir un groupe de containers avec la même IP. La communication entre les container dans un pods passent alors par localhost :
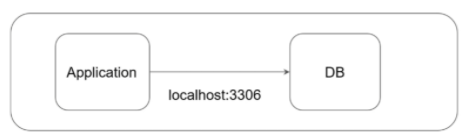
Exemple:
apiVersion: v1
kind: Pod
metadata:
name: multi-container-pod
spec:
containers:
- name: nginx-container
image: nginx:latest
ports:
- containerPort: 80
- name: busybox-container
image: radial/busyboxplus:curl
command:
- "sh"
- "-c"
- "while true; do echo 'BusyBox is running'; sleep 10; done"
Création du pod avec 2 containers :
kubectl create -f multi-container.yml
exec dans le container busybox-container afin de tester la connectivité avec le container nginx-container :
$ kubectl exec -it multi-container-pod -c busybox-container -- ash
[ root@multi-container-pod:/ ]$ ls
bin/ dev/ etc/ home/ lib/ lib64 linuxrc media/ mnt/ opt/ proc/ root/ run sbin/ sys/ tmp/ usr/ var/
[ root@multi-container-pod:/ ]$ curl localhost
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
¶ Pod-to-Pod :
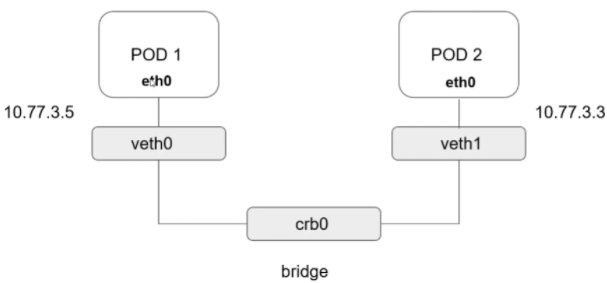
Si l’on regarde sur un noeud via un ip a, on aura plusieurs eth<id> qui seront reliés à un bridge.
$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
2: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN group default
link/ether 02:42:23:76:96:b3 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
3: kube-bridge: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN group default qlen 1000
link/ether b2:10:71:b8:46:7f brd ff:ff:ff:ff:ff:ff
98248: eth0@if98249: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 0a:ac:68:ee:b7:b4 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 192.168.0.13/23 scope global eth0
valid_lft forever preferred_lft forever
98252: eth1@if98253: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:12:00:10 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.16/16 scope global eth1
valid_lft forever preferred_lft forever
Afin de tester le réseau, nous allons créer un déploiement (nous verrons ça un peu plus tard) qui exécute 2 pods nginx.
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.25.2
ports:
- containerPort: 80
Comme tout objet Kubernetes, on peut get les déploiements :
$ kubectl get deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx 2/2 2 2 11s
On peut aussi describe le déploiement :
$ kubectl describe deploy
Name: nginx
Namespace: default
CreationTimestamp: Wed, 30 Aug 2023 09:19:38 +0000
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=nginx
...
On va maintenant récupérer les IPs des 2 pods nginx :
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-69c866fc5d-bq8wg 1/1 Running 0 2m41s 10.5.1.5 node2 <none> <none>
nginx-69c866fc5d-wkcqg 1/1 Running 0 2m41s 10.5.1.4 node2 <none> <none>
On va ensuite créer un pod avec une image busybox afin de pouvoir tester la connectivité entre les pods (ping, curl) :
apiVersion: v1
kind: Pod
metadata:
name: busybox
spec:
containers:
- name: busybox
image: radial/busyboxplus:curl
args:
- sleep
- "1000"
On va ensuite exécuter un ping + un curl sur l'IP d'un serveur nginx. Pour se faire nous allons utiliser la commande kubectl exec :
$ kubectl exec busybox -- ping 10.5.1.5
PING 10.5.1.5 (10.5.1.5): 56 data bytes
64 bytes from 10.5.1.5: seq=0 ttl=64 time=0.326 ms
64 bytes from 10.5.1.5: seq=1 ttl=64 time=0.110 ms
64 bytes from 10.5.1.5: seq=2 ttl=64 time=0.086 ms
^C
$ kubectl exec busybox -- ping 10.5.1.4
PING 10.5.1.4 (10.5.1.4): 56 data bytes
64 bytes from 10.5.1.4: seq=0 ttl=64 time=0.317 ms
64 bytes from 10.5.1.4: seq=1 ttl=64 time=0.115 ms
64 bytes from 10.5.1.4: seq=2 ttl=64 time=0.188 ms
$ kubectl exec busybox -- curl -s 10.5.1.5
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
On voit donc, que sans configuration précise, le pod busybox peut contacter les autres pods !
¶ Pod-to-Service :
On sait qu’un service aura une IP et un DNS :
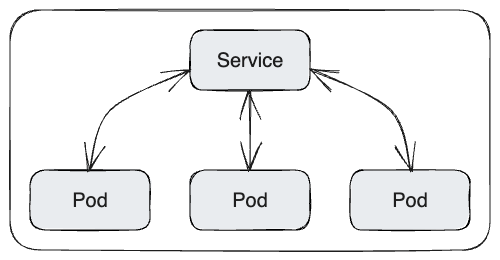
- Flux d’entrée sur le port X
- Le flux arrive sur le service
- Le service distribue le trafic vers les X pods
On va garder le même déploiement nginx que dans l'exemple précédent. On va aussi garder le pod busybox.
A cela on va ajouter un service :
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80
Après l'avoir apply/create :
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 46m
nginx-service ClusterIP 10.97.203.91 <none> 80/TCP 4m36s
Puis on va s'exec dans le pod busybox et essayer de contacter le service de différentes manières :
$ kubectl exec -it busybox -- sh
[ root@busybox:/ ]$ curl 10.97.203.91
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
[ root@busybox:/ ]$ curl nginx-service
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
[ root@busybox:/ ]$ curl nginx-service.default.svc.cluster.local
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
...
Il y a donc différentes manières d'atteindre le service :
- Directement via son IP
- Via le nom du service
- Via le DNS kubernetes
<service>.<namespace>.svc.cluster.local
¶ Internet-to-Service :
Aussi appelé ingress, Kubernetes ingress est une collection de règles de routages qui décide de comment les utilisateurs externes accèdent aux services qui tournent dans le cluster :
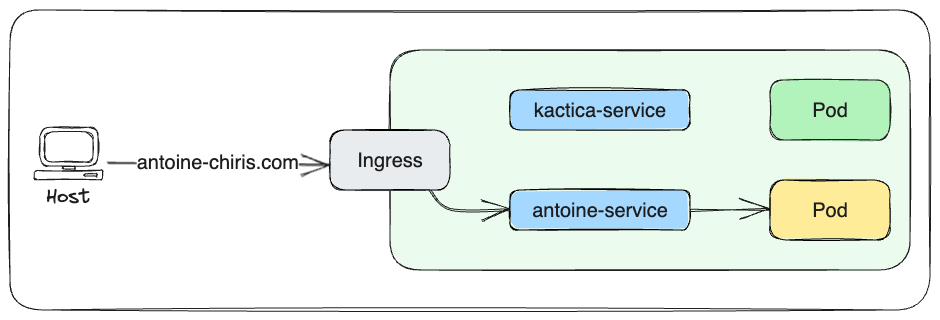
- Ici on veut accéder à antoine-chiris.com → ingress redirige vers example-service qui lui dirige vers POD jaune
- On aurait pu accéder à kactica.com → l'ingress aurait regirigé vers kactica-service puis vers POD vert
¶ Aperçu des ReplicaSets :
Le but d’un ReplicaSet est de maintenir un état stable de réplica à n’importe quel moment :
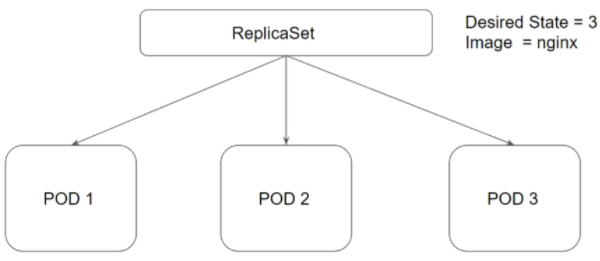
Il faut différencier 2 paramètres du ReplicaSet :
- Desired State : Le nombre de pods désiré
- Current State : Le nombre de pods qui sont en train de tourner
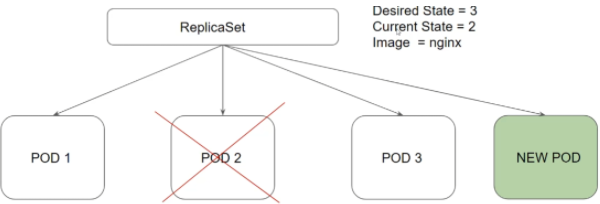
En pratique :
$ kubectl get replicaset -A
NAMESPACE NAME DESIRED CURRENT READY AGE
kube-system coredns-5d78c9869d 2 2 0 23m
¶ Notre premier ReplicaSet
Nous allons ajouter un ReplicaSet à un fichier YAML :
apiVersion: apps/v1
kind: ReplicaSet # Type
metadata:
name: test-replica # Nom du ReplicaSet
spec:
replicas: 3 # DesiredState
selector:
matchLabels: # Match le label tier:frontend ci-dessous
tier: frontend
template: # Va utiliser api v1, kind Pod
metadata:
labels:
tier: frontend # Ajoute le label tier: frontend aux pods
spec: # Spec du container
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
Ici nous utilisons l’api : apps/v1 avec un type ReplicaSet et non Pod comme on n’a pu le faire précédemment
On peut supprimer un pod via kubectl delete pod nom_du_pod celui-ci sera recréé pour respecter le DesiredState de 3 !
$ kubectl delete pod test-replica-jdvxb
pod "test-replica-jdvxb" deleted
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
test-replica-sqw9t 1/1 Running 0 4m52s
test-replica-wf5bz 1/1 Running 0 3s
test-replica-xmwjb 1/1 Running 0 4m52s
Pour supprimer le ReplicaSet :
kubectl delete replicaset test-replica
On peut décrire le ReplicaSet :
$ kubectl describe replicaset test-replica
Name: test-replica
Namespace: default
Selector: tier=frontend
Labels: <none>
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: tier=frontend
Containers:
php-redis:
Image: gcr.io/google_samples/gb-frontend:v3
Port: <none>
Host Port: <none>
Environment: <none>
Mounts: <none>
Volumes: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 6m6s replicaset-controller Created pod: test-replica-jdvxb
Normal SuccessfulCreate 6m6s replicaset-controller Created pod: test-replica-xmwjb
Normal SuccessfulCreate 6m5s replicaset-controller Created pod: test-replica-sqw9t
Normal SuccessfulCreate 77s replicaset-controller Created pod: test-replica-wf5bz
On peut voir que notre pod a été remplacé il y a 77s (lorsque j'ai supprimé le pod test-replica-jdvxb)
¶ Les déploiements
Les pods c'est bien... Mais comment je peux faire pour automatiser le scaling d'un pod, les rolling updates... ? La réponse : Les déploiements ! On en a utilisé au-dessus, sans en expliquer son fonctionnement, c'est le moment !
Le Deployment est un type d'objet Kubernetes qui permet d'automatiser le management des pods. Un déploiement permet de spécifier un "statut". Le cluster fera en sorte d'avoir ce statut en continu.
Exemple :
- Scaling : Avec un déploiement on peut spécifier le nombre de réplicas (comme on l'a fait au-dessus avec nginx)
- Rolling updates : Avec un déploiement, on peut changer la version de l'image. Lors de la mise à jour de l'image, cela va changer progressivement les anciens pods par les nouveaux afin de ne pas perdre la disponibilité de l'application.
- Self healing : Si un pod est détruit (accidentellement ou erreur), le déploiement va immédiatement reprogrammer un nouveau pod.
Nous allons reprendre l'exemple du déploiement nginx avec les explications cette fois-ci :
apiVersion: apps/v1
kind: Deployment # Type d'objet
metadata:
name: nginx-deploy # Nom du pod nginx-deploy-ID
labels:
app: nginx # Label afin d'identifier le déploiement
spec:
replicas: 2 # Déploie 2 pods
selector:
matchLabels:
app: nginx # Match tous les pods qui ont le label app: nginx
template:
metadata:
labels:
app: nginx # Ajoute un label aux pods généré par le déploiement
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
Une fois crée (kubectl apply -f ou kubectl create -f) on va voir si le déploiement s'est bien déroulé :
$ kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-deploy 2/2 2 2 115s
On peut aussi décrire le déploiement :
$ kubectl describe deployment nginx-deploy
Name: nginx-deploy
Namespace: default
CreationTimestamp: Wed, 30 Aug 2023 15:19:07 +0000
Labels: app=nginx
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=nginx
Replicas: 2 desired | 2 updated | 2 total | 2 available | 0 unavailable
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 2m10s deployment-controller Scaled up replica set nginx-deploy-57d84f57dc to 2
Un déploiement crée automatiquement un ReplicaSet qui va permettre de gérer le nombre de pods du déploiement :
$ kubectl get replicaset # ou get rs
NAME DESIRED CURRENT READY AGE
nginx-deploy-57d84f57dc 2 2 2 2m43s
On va maintenant lister les pods :
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deploy-57d84f57dc-krrhq 1/1 Running 0 3m24s
nginx-deploy-57d84f57dc-wdwxb 1/1 Running 0 3m24s
Si je supprime un des pods on va voir que le déploiement va automatiquement redémarrer un pod dans la foulée :
$ kubectl delete pod nginx-deploy-57d84f57dc-krrhq
pod "nginx-deploy-57d84f57dc-krrhq" deleted
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deploy-57d84f57dc-wdwxb 1/1 Running 0 3m44s
nginx-deploy-57d84f57dc-xdpkt 1/1 Running 0 3s
On va maintenant éditer le nombre de replicas dans le fichier de configuration puis appliquer :
$ vim deploy-nginx.yml
...
replicas: 4
...
$ kubectl apply -f deployment.yml
deployment.apps/nginx-deploy configured
$ kubectl get replicaset
NAME DESIRED CURRENT READY AGE
nginx-deploy-57d84f57dc 4 4 4 4m35s
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-deploy-57d84f57dc-2zgsg 1/1 Running 0 8s
nginx-deploy-57d84f57dc-r7rgm 1/1 Running 0 8s
nginx-deploy-57d84f57dc-wdwxb 1/1 Running 0 4m38s
nginx-deploy-57d84f57dc-xdpkt 1/1 Running 0 57s
kubectl apply va permettre d'appliquer un changement effectué dans le fichier de configuration.
On voit que le déploiement est bien passé à 4 pods. Si on décrit le déploiement on va voir un événement lié à ce changement :
$ kubectl describe deployment nginx-deploy
...
OldReplicaSets: <none>
NewReplicaSet: nginx-deploy-57d84f57dc (4/4 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 5m16s deployment-controller Scaled up replica set nginx-deploy-57d84f57dc to 2
Normal ScalingReplicaSet 46s deployment-controller Scaled up replica set nginx-deploy-57d84f57dc to 4 from 2
¶ Rolling Updates
Lorsque l'on doit mettre à jour l'image d'un déploiement, nous allons modifier la configuration du déploiement :
$ kubectl edit deployment nginx-deploy
deployment.apps/nginx-deploy edited
On va modifier l'image du déploiement puis quitter (:wq). A ce moment là. Un nouveau ReplicaSet va être crée afin de passer progressivement sur la nouvelle version :
$ kubectl get replicaset
NAME DESIRED CURRENT READY AGE
nginx-deploy-57d84f57dc 3 3 3 6m47s
nginx-deploy-f64d4cdb5 2 2 0 7s
[node1 ~]$ kubectl get replicaset
NAME DESIRED CURRENT READY AGE
nginx-deploy-57d84f57dc 3 3 3 6m50s
nginx-deploy-f64d4cdb5 2 2 2 10s
[node1 ~]$ kubectl get replicaset
NAME DESIRED CURRENT READY AGE
nginx-deploy-57d84f57dc 0 0 0 6m52s
nginx-deploy-f64d4cdb5 4 4 4 12s
Progressivement, le nouveau ReplicaSet remplace l'ancien.
Important à savoir :
Un déploiement assure qu’un certain nombre de pods soient down au moment de la mise à jour.
- Par défaut, le déploiement assure qu’il y ait 25% de pods UP (25% max non disponible)
- Les déploiements garde un historique de ce qui a été fait, describe ainsi que rollout :
$ kubectl describe deployments nginx-deploy
$ kubectl rollout history deployment nginx-deploy
Comme vous le voyez, change-cause est à none car par défaut, kubernetes ne va pas mettre à jour ce champ. Nous avons plusieurs solutions :
- Ajouter une annotation
kubernetes.io/change-causà notre déploiement (peut se faire après la mise à jour) - Utiliser le paramètre
--recordlors du changement de l'image (se fait AVANT la mise à jour)
$ kubectl annotate deployment nginx-deploy kubernetes.io/change-cause="Changed nginx image to version 1.20"
# OU
kubectl set image deployment/nginx-deploy nginx=nginx:1.20 --record
¶ Configuration d'un déploiement
Pendant un rolling update il y a deux paramètres très importants :
- maxSurge: Le nombre de pods maximum au dessus du nombre de pods original (Si on met 2 sur un deployment de 3 on montera donc maximum à 5 lors du rollingUpdate)
- maxUnavailable: Le nombre de pods maximum qui peuvent être non disponible pendant le rolling update
Exemples :
- maxUnavailabe=0 et maxSurge=20% → Capacité maximale conservée
- maxUnavailabe=10% et maxSurge=0 → Update sans pod en plus.
Si on veut un update rapide → utiliser le maxSurge
S’il y a un quota de ressources qui est mis en place et que nous pouvons nous permettre une indisponibilité… maxUnavailable peut être utilisé.
Testons sur notre déploiement :
$ kubectl get deployment nginx-deploy -o yaml
apiVersion: apps/v1
kind: Deployment
...
spec:
...
strategy:
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
type: RollingUpdate
-o yaml va nous sortir la configuration du déploiement sous forme YAML. On peut y voir la stratégie.
On va éditer ce déploiement via la commande :
$ kubectl edit deployment nginx
Cette commande va ouvrir vim et nous pouvons modifier le déploiement à la volée ! (:wq va automatiquement appliquer les changements).
¶ DaemonSets
Les DaemonSets vont permettre de lancer un pod sur chaque noeud du cluster. Si on ajoute un noeud au cluster, le pod sera aussi ajouté à ce cluster !
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: my-daemonset
spec:
selector:
matchLabels:
app: my-ds
template:
metadata:
labels:
app: my-ds
spec:
containers:
- name: busybox
image: busybox
command: ["sh", "-c", "while true; do sleep 10; done"]
On peut ensuite avoir le statut du daemonset (ds) et la description (kubectl describe daemonset my-daemonset)
$ kubectl get ds
NAMESPACE NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
default my-daemonset 2 2 2 2 2 <none> 2m11s
# Voir l'emplacement
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-daemonset-4x7f2 0/1 ContainerCreating 0 18s <none> node3 <none> <none>
my-daemonset-94d8z 1/1 Running 0 54s 10.5.1.18 node2 <none> <none>
Un daemonset peut être utilisé pour le logging de chaque noeud par exemple (fluentd).
¶ Scheduling : taints et tolérances
Les "taints" contrôle la façon dont le pod va être autorisé à tourner sur un noeud.
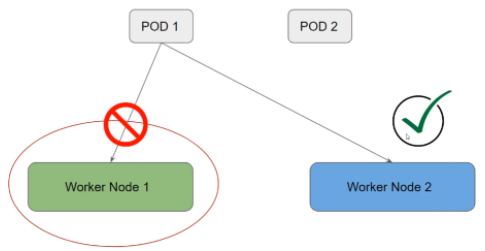
Les pods peuvent avoir une tolérance, ce qui annule la taint pour ce pod.
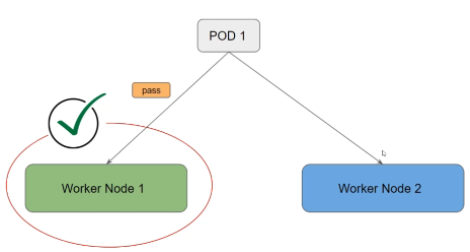
Chaque taint a son utilité.
- NoExecute (utilisable lors d'une maintenance par exemple) :
- Empêche les nouveaux pods d'être programmé sur ce noeud.
- Enlève les pods existants sur le noeud
Dans les spec d'un container, on peut spécifier des demandes de ressources (resource requests) pour des ressources du type RAM / CPU.
Le scheduler ne mettra pas un pod sur un noeud qui n'a pas les ressources nécessaires.
apiVersion: v1
kind: Pod
metadata:
name: busybox-ressource
spec:
containers:
- name: busybox
image: radial/busyboxplus:curl
command: ["sh", "-c", "while true; do sleep 3600; done"]
resources:
requests:
memory: 64Mi
cpu: 250m
Pour ajouter une taint sur un noeud :
$ kubectl taint nodes node3 key=value:NoExecute
node/node3 tainted
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
my-daemonset-4x7f2 1/1 Terminating 0 4m49s
my-daemonset-94d8z 1/1 Running 0 5m25s
On voit que directement, le pod va être supprimé du node3.
On peut aussi appliquer une tolérance à un pod :
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-tolerations
spec:
replicas: 2
selector:
matchLabels:
app: nginx-tolerations
template:
metadata:
labels:
app: nginx-tolerations
spec:
containers:
- name: nginx-container
image: nginx:latest
tolerations:
- key: "key"
operator: "Exists"
effect: "NoExecute"
Pour enlever cette taint il faut ajouter un - :
$ kubectl taint nodes node3 key=value:NoExecute-
node/node3 untainted
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
my-daemonset-94d8z 1/1 Running 0 6m48s
my-daemonset-xsnhz 0/1 ContainerCreating 0 2s
¶ Healthcheck / Probes
Les sondes (probes) vont nous permettre de définir l'état d'un container.
Il existe différents types de probes :
Liveness Probes : vérifie que le container soit healthy, il détecte et remédie à cette situation :
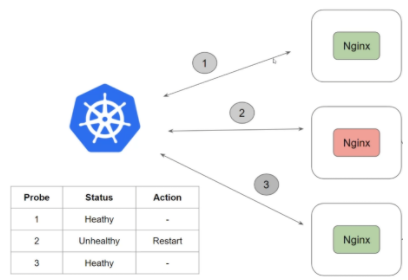
Il existe 3 types de check :
- HTTP
- Command
- TCP
Readiness Probes : vérifie que le container soit up et tourne bien.
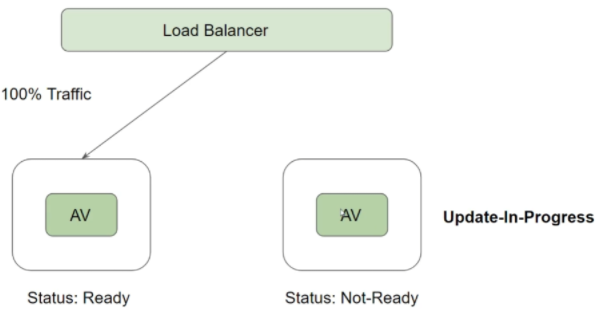
apiVersion: apps/v1
kind: Deployment
metadata:
name: probe-deployment
spec:
replicas: 3 # Vous pouvez ajuster le nombre de réplicas selon vos besoins
selector:
matchLabels:
app: probe-app
template:
metadata:
labels:
app: probe-app
spec:
containers:
- name: nginx
image: nginx:latest
ports:
- containerPort: 80
livenessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 3 # Attend 3s au lancement du pod avant de lancer la vérification de livenessProbe
periodSeconds: 3
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 3
periodSeconds: 3
Si on utilise un service associé à ce déploiement. Celui-ci ne redirigera pas les flux tant que le pod n'est pas prêt.
En décrivant le déploiement :
$ kubectl describe deployments.apps probe-deployment
...
Liveness: http-get http://:80/ delay=3s timeout=1s period=3s #success=1 #failure=3
Readiness: http-get http://:80/ delay=3s timeout=1s period=3s #success=1 #failure=3
¶ Services et DNS
On a maintenant X pods nginx... Chacun avec une IP privée. C'est bien beau mais personne ne peut y accéder à part nous. Grâce au service nous allons pouvoire exposer les pods sur une seule IP. Il se chargera de faire le Load Balancing sur les pods.
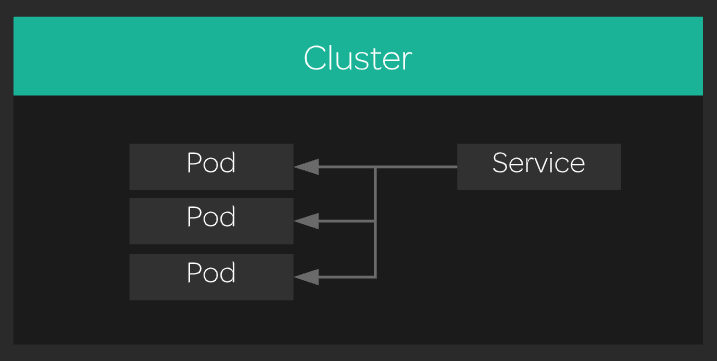
(source: LinuxAcademy)
On va maintenant créer un service afin d'accéder à nginx :
apiVersion: v1
kind: Service # Type d'objet
metadata:
name: nginx-service # Nom du service
spec:
selector:
app: nginx # Le service va chercher tous les pods avec le label app: nginx
ports:
- protocol: TCP
port: 80
targetPort: 80 # Port du container sur lequel tourne nginx
nodePort: 30080
type: NodePort # Expose un port (ici 30080) à l'extérieur du cluster.
Le service aura une IP et nginx sera exposé sur le port 30080. Le service s'occupera de rediriger le trafic entre les 3 pods nginx.
Il existe différents types de services. Ici nous utilisons NodePort. Voici les différents types de services :
- ClusterIp (défaut) : Expose le/les pods sur une seule IP unique dans le cluster.
- NodePort : Expose le service en dehors du cluster sur chaque noeud du cluster. Ce type de service utilise un port spécifique (30080 dans notre exemple), entre entre 30000-32767
- LoadBalancer : Expose le service en dehors du cluster sur un Load Balancer d'un cloud provider (AWS, GCP...). Ce type de service n'utilise donc pas le LB k8s.
- ExternalName : Expose une ressource externe dans le cluster en utilisant le DNS.
kubectl create -f service-nginx.yml
On va maintenant vérifier que tout est bon :
$ kubectl get svc # ou kubectl get service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 6h57m
nginx-service NodePort 10.107.95.178 <none> 80:30080/TCP 28s
Je peux maintenant accéder à nginx via mon IP Publique sur le port 30080 : http://xx.xx.xx.645:30080/
Mais aussi en localhost depuis n'importe quel noeud : curl localhost:30080
¶ DNS
Comme nous avons pu voir dans la connexion Pod-to-Service Kubernetes inclut un DNS dans le cluster :
- Les pods dans le même "namespace" pourront utiliser le nom du service comme nom de domaine pour communiquer avec les autres pods : curl nginx-service ou curl nginx-service.default.svc.cluster.local
Si le service est dans un autre namespace (ex: my-namespace) :
- curl my-svc.my-namespace.svc.cluster.local
¶ Introduction aux labels et aux selecteurs
Les labels sont des paires clé/valeurs qui sont attachées à des objets comme des pods.
Les labels sont très importants pour retrouver facilement les pods.
Les “Selectors” vont nous permettre de filtrer les objets via les labels :
- On peut donc lui dire “montre moi les objets qui ont un label env:prod”
kubectl get pods -l env=prod
¶ Mise en place des labels et des selecteurs
Pour ajouter un label à un pod :
kubectl label pods nginx-pod env=dev
Pour afficher les labels dans la liste des pods :
kubectl get pods --show-labels
Récupérer les pods avec le label env=prod :
kubectl get pods -l env=prod
On peut aussi filtrer sur les pods qui n’ont pas env=prod :
kubectl get pods -l env!=prod
On peut aussi créer des labels directement dans le fichier de configuration :
apiVersion: v1
kind: Pod
metadata:
name: nginxwebserver
labels: # Ici on mettra les labels sous la forme key: value
env: prod
app: nginx
spec:
containers:
- image: nginx
name: democontainer
¶ Requests et Limits avec Kubernetes
Lors du déploiement d’une grosse application il peut être nécessaire de limiter les ressources.
- Request : Ressource garantie
- Limits : Ne prend pas plus de ressource que cette limite
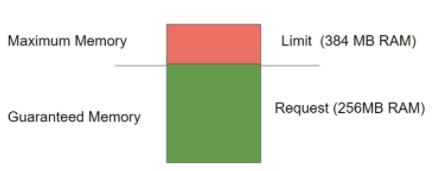
Exemple :
apiVersion: v1
kind: Pod
metadata:
name: nginx-resources
spec:
containers:
- name: k8s-container
image: nginx
resources:
requests:
memory: "64Mi"
cpu: "0.5"
limits:
memory: "128Mi"
cpu: "1"
En regardant la description du pod :
$ kubectl describe pod nginx-resources
...
Limits:
cpu: 1
memory: 128Mi
Requests:
cpu: 500m
memory: 64Mi
...
Le scheduler vérifiera toujours qu’il y ait assez de ressource avant de mettre en place le pod. Celui-ci restera en pending s'il n'y a pas assez de resources, par exemple si on request 16 CPU on aura ce message dans le describe :
Warning FailedScheduling 11s default-scheduler 0/3 nodes are available: 1 Insufficient cpu, 1 node(s) had untolerated taint {key: value}, 1 node(s) had untolerated taint {node-role.kubernetes.io/control-plane: }. preemption: 0/3 nodes are available: 1 No preemption victims found for incoming pod, 2 Preemption is not helpful for scheduling..
¶ Network policies
Par défaut les pods ne sont pas isolés et acceptent le trafic venant de n’importe quelle source.
- pod1 peut communiquer avec pod2
- pod1 dans le namespace DEV peut communiquer avec le pod3 dans le namespace Staging
En prod, c’est mieux d’éviter celà.
¶ Comment fonctionnent les Network Policies ?
Les Network Policies fonctionnent en définissant des règles de trafic entrant (ingress) et sortant (egress) pour un groupe de pods. Ces règles sont appliquées par le plugin réseau (CNI) utilisé dans le cluster Kubernetes. Voici les concepts clés :
- PodSelector : Sélectionne les pods auxquels la politique s'applique.
- Ingress Rules : Définissent les sources autorisées à envoyer du trafic aux pods sélectionnés.
- Egress Rules : Définissent les destinations autorisées pour le trafic sortant des pods sélectionnés.
- NamespaceSelector : Permet de sélectionner des pods dans d'autres namespaces.
- IPBlock : Permet de définir des règles basées sur des plages d'adresses IP.
Une politique réseau est une spécification de comment un groupe de pods est autorisé à communiquer avec les autres.
- pod1 peut uniquement communiquer avec pod5 du même namespace
- pod2 peut uniquement communiquer avec pod10 qui est sur le namespace Security
- Personne ne communique avec le pod3
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-pod
namespace: default
spec:
podSelector:
matchLabels:
role: db # Applique la règle aux pods ayant role: db
policyTypes: # Ingress / Egress
- Ingress
Cette règle bloque tout le trafic entrant (Ingress) vers les pods ayant le label role: db dans le namespace default. C'est une politique "default deny", car elle n'a pas de règles d'entrée spécifiées, ce qui signifie qu'aucun trafic entrant n'est autorisé par défaut.
Explication de l'exemple
podSelector: Sélectionne tous les pods dans le namespace frontend.ingress: Définit les règles de trafic entrant.from: Spécifie que le trafic peut provenir de pods dans le namespace backend.ports: Autorise le trafic sur le port 80 en utilisant le protocole TCP.
Voici un exemple de Network Policy simple qui permet à tous les pods dans un namespace nommé frontend de recevoir des connexions sur le port 80 de tous les pods dans un namespace nommé backend:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: backend-to-frontend
namespace: frontend
spec:
podSelector: {}
ingress:
- from:
- namespaceSelector:
matchLabels:
name: backend
ports:
- protocol: TCP
port: 80
Comme d’habitude on peut lister toutes les NetworkPolicy :
kubectl get networkpolicy
¶ Volumes
Kubernetes utilise des volumes afin de fournir du stockage pour les containers. Les volumes sont persistants, si un container redémarre, les données seront gardées.
Un même volume peut être monté sur plusieurs containers.
Il y a différents types de volumes :
- NFS : Stockage partagé via le réseau
- hostPath : Souvent pour tester, les fichiers sont stockés dans un dossier du worker. Les fichiers ne sont pas partagés avec les autres noeuds.
- emptyDir : Stockage temporaire qui est supprimé si le pod est supprimé. Très utile pour partager de simples stockages entre les containers dans un pod.
apiVersion: v1
kind: Pod
metadata:
name: volume-pod
spec:
restartPolicy: Never
containers:
- name: busybox
image: busybox
command: ["sh", "-c", "echo \"Successful output!\" > /output/output.txt"]
volumeMounts: # Appel du volume crée en dessous pour le monter dans le container
- name: host-vol # appel du volume déclaré plus bas
mountPath: /output # Monte le volume /output dans le container
volumes: # Déclaration du volume
- name: host-vol # Nom du volume
hostPath:
path: /tmp/output # Crée un dossier /tmp/output sur le noeud sur lequel tourne le pod
Le volume sera crée que sur le noeud qui fait tourner le pod ! Aucun fichier ne sera crée sur les autres noeuds.
[node2 ~]$ ls /tmp/
output
[node2 ~]$ cat /tmp/output/output.txt
Successful output!
[node3 ~]$ ls /tmp/
# Empty
¶ PersistentVolumes
Ici nous allons parler des PersistentVolumes (type d'objet k8s). Le PV permet de définir des ressources de stockage, ainsi, plus tard nous pourront réclamer (PersistentVolumeClaim) ces stockages pour utiliser dans un pod.
Un PersistentVolumeClaim est une requête faite afin de monter un volume sur un container dans un pod.
Un PersistentVolume possède une politique de récupération (Reclaim Policy) qui détermine quoi faire du volume lorsque la PVC est supprimée :
- Retain : Garde le volume et ses données. Autorise la récupération manuelle des données. L'administrateurs est responsable du nettoyage de ce PV.
- Delete : Supprime le PV ainsi que tout ce qui est lié (comme l'objet de stockage du cloud provider)
- Recycle : Supprime les datas du PV et autorise le PV à être réutilisé (déprécié, utiliser plutot Delete).
On peut étendre un PersistentVolumeClaim simplement en éditant l'objet. Cependant il faut que la storageClass autorise le allowVolumeExpansion (le passer à true).
On va donc essayer cela. Nous allons dans un premier temps créer une StorageClass qui permet aux administrateurs de décrire les "classes" de stockage qu'ils proposent. On va par exemple avoir la classe HDD, SSD, Hybride...
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: localdisk
provisioner: kubernetes.io/no-provisioner
Les providers comme GCP / Azure / AWS permettent le redimensionnement dynamique des disques, il est nécessaire d'ajouter le paramètre suivant : allowVolumeExpansion: true au StorageClass
On va afficher nos storageClass :
$ kubectl get storageclass # ou kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
localdisk kubernetes.io/no-provisioner Delete Immediate true 6s
On va ensuite créer un PersistentVolume (PV) :
kind: PersistentVolume
apiVersion: v1
metadata:
name: my-pv
spec:
storageClassName: localdisk
persistentVolumeReclaimPolicy: Delete
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
hostPath:
path: /tmp/pvoutput
On affiche les PersistentVolume :
$ kubectl get persistentvolume # ou kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
my-pv 1Gi RWO Delete Available localdisk 4s
Enfin nous allons créer notre PVC :
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
storageClassName: localdisk
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 100Mi
On liste les pvc :
$ kubectl get persistentvolumeclaim # ou kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
my-pvc Bound my-pv 1Gi RWO localdisk 3s
Ici on voit que le PVC a pris le disque de 1Gi directement car il correspondait à sa demande.
On va maintenant voir comment créer un pod avec un appel au PVC crée au-dessus :
apiVersion: v1
kind: Pod
metadata:
name: pvc-pod # nom du pod
spec:
containers:
- name: busybox # nom du container
image: busybox
command: ['sh', '-c', 'while true; do echo "Successfully written to log." >> /output/output.log; sleep 10; done']
volumeMounts:
- name: pv-storage # Nom du volume déclaré ci-dessous
mountPath: /output
volumes:
- name: pv-storage # Nom du volume
persistentVolumeClaim: # On fait appel à un PVC
claimName: my-pvc # nom du PVC : soit requête de 100m de disque sur la storageclass localdisk en accès Lecture/Ecriture
Je vais maintenant supprimer mon pod et mon PVC :
- kubectl delete pod pvc-pod
- kubectl delete pvc my-pvc
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
my-pv 1Gi RWO Delete Released default/my-pvc localdisk 31m
on voit maintenant que la PV n'est plus en statut "lié" (bound) mais en statut libéré (released).
¶ ConfigMaps et Secrets
Afin de gérer la configuration d'une application, nous pouvons passer en paramètre des ConfigMaps.
Kubernetes utilise ConfigMaps ainsi que Secrets afin de stocker les informations et les envoyer sur un container.
- ConfigMaps : Stocke des données au format clé/valeur. Les données peuvent être une simple valeur ou un fichier de configuration entier !
- Secrets : Equivalent à ConfigMaps, sauf que les données sont encodés en base64. On utilise les Secrets pour des données sensibles comme des mots de passes, des tokens...
Imaginons une AppA dans un container, selon l’environnement les paramètres peuvent changer (prod/dev).
Exemple :
- Dev environnement :
app.env=dev
app.mem=2048m
app.properties=dev.env.url
- Prod environnement :
app.env=prod
app.mem=8096m
app.properties=prod.env.url
Au lieu de "hard coder" ces infos dans l’application, on va donc centraliser les paramètres dans une ConfigMap.
L’avantage des ConfigMaps c’est que l’on peut ajouter dynamiquement des paramètres (on peut par exemple rajouter app.cpu=1 quand on le souhaite)
Voici un exemple de ConfigMaps :
apiVersion: v1
kind: ConfigMap
metadata:
name: my-configmap
data:
app.env: dev
# Va monter le fichier key2.txt dans le container
key2.txt: |
Another value
multiple lines
more lines
On peut évidemment avoir la liste et la description de cet objet :
$ kubectl get configmaps
NAME DATA AGE
kube-root-ca.crt 1 122m # ConfigMaps par défaut de k8s
my-configmap 2 6s
$ kubectl describe cm my-configmap
Name: my-configmap
Namespace: default
Labels: <none>
Annotations: <none>
Data
====
app.env:
----
dev
key2.txt:
----
Another value
multiple lines
more lines
BinaryData
====
Events: <none>
Les Secrets sont utilisés pour les informations sensibles (password BDD, Token API...).
Voici un exemple de Secrets :
apiVersion: v1
kind: Secret
metadata:
name: my-secret # Nom du secret
type: Opaque # Type de secret
data: # encodé en Base64
username: dXNlcgo= # Base64
password: TWVyY2kgZGUgbGlyZSBtb24gd2lraSA6KQ== # Base64
On peut encoder/décoder en base64 ici
Pour fournir un username/password en texte il faut utiliser le paramètre stringData.
Il existe différents types de secret, on peut les retrouver ici
On peut lister/décrire les secrets via les commandes suivantes :
$ kubectl get secrets
NAME TYPE DATA AGE
default-token-m5vr2 kubernetes.io/service-account-token 3 23h # secret par défaut
my-secret Opaque 2 6s
$ kubectl describe secrets my-secret
Name: my-secret
Namespace: default
Labels: <none>
Annotations: <none>
Type: Opaque
Data
====
password: 25 bytes
username: 5 bytes
Pour passer les ConfigMaps/Secrets à un container nous avons plusieurs façon de le faire :
- env : Les valeurs seront passées sous forme de variable d'environnement
- volume : Les configurations seront montées sous forme de volumes dans le container (sous forme de fichier)
Dans l'exemple ci-dessous je vais passer les configMaps/secrets via env et via les volumes :
apiVersion: v1
kind: Pod
metadata:
name: my-secret-pod
spec:
restartPolicy: Never # Pod unique
containers:
- name: busybox
image: busybox
# Commande qui va afficher les configmaps + secrets
command: ["sh", "-c", "echo \"ConfigMap environment variable: $CONFIGMAPVAR\" && echo \"Secret environment variable: $SECRETVAR\" && echo \"The ConfigMap mounted file is: $(cat /etc/configmap/key2.txt)\" && echo \"The Password is:\" $(cat /etc/secret/password) && echo \"List of files in /etc/configmap/:\" $(ls /etc/configmap/) && echo \"List of files in /etc/secret/:\" $(ls /etc/secret/)"]
env: # On va passer les configmaps/secrets via la méthode env
- name: CONFIGMAPVAR # Nom qu'on veut donner à la variable
valueFrom:
configMapKeyRef: # fait référence à une configmap déjà créée
name: my-configmap
key: app.env # On récupère la valeur de app.env
- name: SECRETVAR # Nom qu'on veut donner à la variable secret
valueFrom:
secretKeyRef: # fait référence à un secret déjà créée
name: my-secret
key: username # On récupère la valeur de username
volumeMounts: # On va monter le volume
- name: configmap-vol
mountPath: /etc/configmap # Le fichier key2.txt sera monté dans ce chemin
- name: secret-vol
mountPath: /etc/secret # le secret "password" sera monté dans ce chemin
volumes: # Déclaration des volumes
- name: configmap-vol # Nom qui doit être repris dans volumeMounts
configMap:
name: my-configmap # Nom de la configMap crée auparavant
- name: secret-vol # Nom qui doit être repris dans volumeMounts
secret:
secretName: my-secret
Une fois cette configuration appliquée (kubectl apply -f config-pod.yml) nous allons regarder les logs de ce pod :
$ kubectl logs my-secret-pod
ConfigMap environment variable: dev
Secret environment variable: user
The ConfigMap mounted file is: Another value
multiple lines
more lines
The Password is: Merci de lire mon wiki :)
List of files in /etc/configmap/: app.env key2.txt
List of files in /etc/secret/: password username
Si l'on veut monter un secret dans un endroit spécifique d'un container :
apiVersion: v1
kind: Pod
spec:
containers:
volumeMounts:
- name: secrets
mountPath: /etc/user-pid
volumes:
- name: secrets
secret:
secretName: user-pid
Comme dit précédemment un Secret est encodé en base64, ce n'est donc pas sécurisé de mettre des secret sur un repository Git ou autre part. Il est donc vivement recommandé d'associé votre cluster avec Sealed Secrets, qui permet de chiffrer/déchiffrer les secrets lorsqu'ils sont appliqués sur le cluster.