¶ Aperçu du scan de container (MSR)
Les conteneurs Docker peuvent présenter des failles de sécurité.
S'ils sont pull à l'aveugle et si les conteneurs fonctionnent en production, cela peut entraîner une faille.
MSR nous permet d'effectuer un scan de sécurité pour les conteneurs (fonctionnalité payante). Voici un compte rendu de scan :
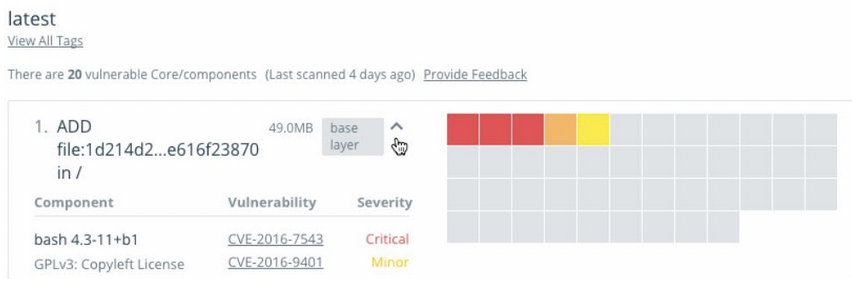
Ces scans peuvent être effectués On Push ou même manuellement.
En cliquant sur view details on pourra voir quelles couches sont affectées par les vulnérabilités. On pourra voir les CVE associées à la vulnérabilité !
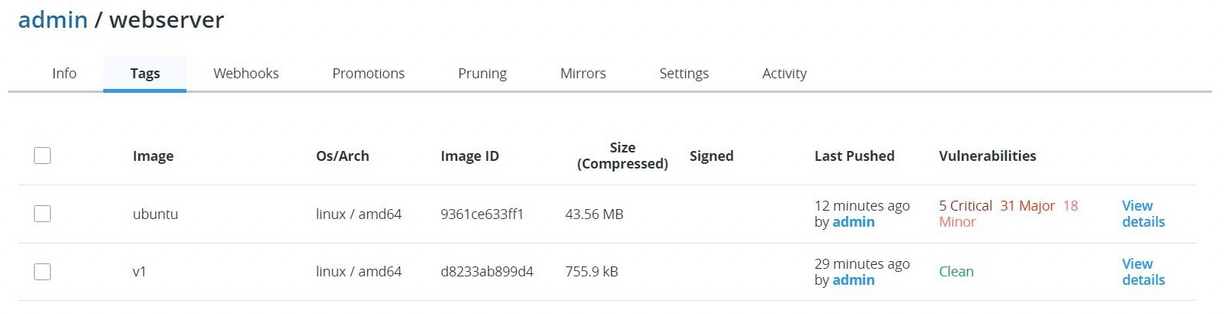
¶ MSR webhooks (MSR)
Vous pouvez configurer DTR pour qu'il envoie automatiquement des notifications post-événement à l'URL d'un webhook de votre choix.

Il y a différents type de webhook (tag pushed, tag pulled, tag deleted, security scan completed…). Via l'interface :
¶ Aperçu du bundle client UCP (MKE)
Un bundle client est un groupe de certificats téléchargeables directement depuis l'interface Mirantis Kubernetes Engine (MKE) de Docker.
En fonction de la permission associée à l'utilisateur, vous pouvez maintenant exécuter des commandes docker swarm depuis votre machine distante qui prennent effet sur le cluster distant.
Par exemple :
- On peut créer un nouveau service dans MKE depuis votre ordinateur portable (sans connexion SSH).
- Connexion au conteneur distant depuis votre ordinateur portable sans SSH (via l'API)
¶ Docker/Kubectl CLI avec le bundle client UCP (MKE)
Le client bundle est associé à un user.
Il faut donc aller dans Profile → Client bundles → New client bundle :
- Cela va télécharger un
.zip - Une fois téléchargé, unziper le bundle. Voici à quoi ressemble son contenu (beaucoup de certificats) :
$ ls
ca.pem cert.pem cert.pub env.cmd env.ps1 env.sh key.pem kube.yml ucp-docker-bundle.zip
- On va maintenant activer l'environnement docker et kubernetes (uniquement si kubectl installé) :
$ eval "$(<env.sh)"
Cluster "ucp_34.77.249.70:6443_admin" set.
User "ucp_34.77.249.70:6443_admin" set.
Context "ucp_34.77.249.70:6443_admin" modified.
- On peut maintenant effectuer des commandes docker/kubectl sur le cluster MKE depuis l'ordinateur local :
$ docker version
...
Server: Mirantis Cloud Native Platform
Engine:
Version: 20.10.13
$ kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system calico-kube-controllers-6c976794f5-9vfts 1/1 Running 1 (73m ago) 8h
kube-system calico-node-2fwds 1/1 Running 1 (73m ago) 8h
kube-system calico-node-cm8v2 1/1 Running 1 (72m ago) 8h
kube-system coredns-fc5599945-znhgr 1/1 Running 1 (73m ago) 8h
kube-system ucp-metrics-tfzrl 2/2 Running 2 (73m ago) 8h
node-feature-discovery ucp-node-feature-discovery-9jxjb 2/2 Running 2 (73m ago) 8h
node-feature-discovery ucp-node-feature-discovery-cct64 2/2 Running 2 (72m ago) 8h
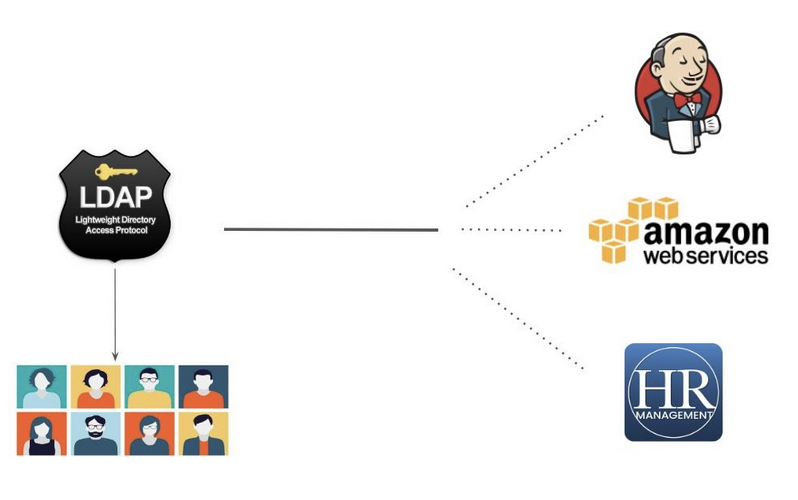
¶ Aperçu de LDAP
Supposons qu'il y ait 500 utilisateurs dans une organisation. Votre organisation utilise 3 services :
- AWS (Infrastructure)
- Jenkins ( CI / CD )
- HR Activator ( Payroll )
On vous a attribué un rôle pour donner aux utilisateurs l'accès aux 3 services :
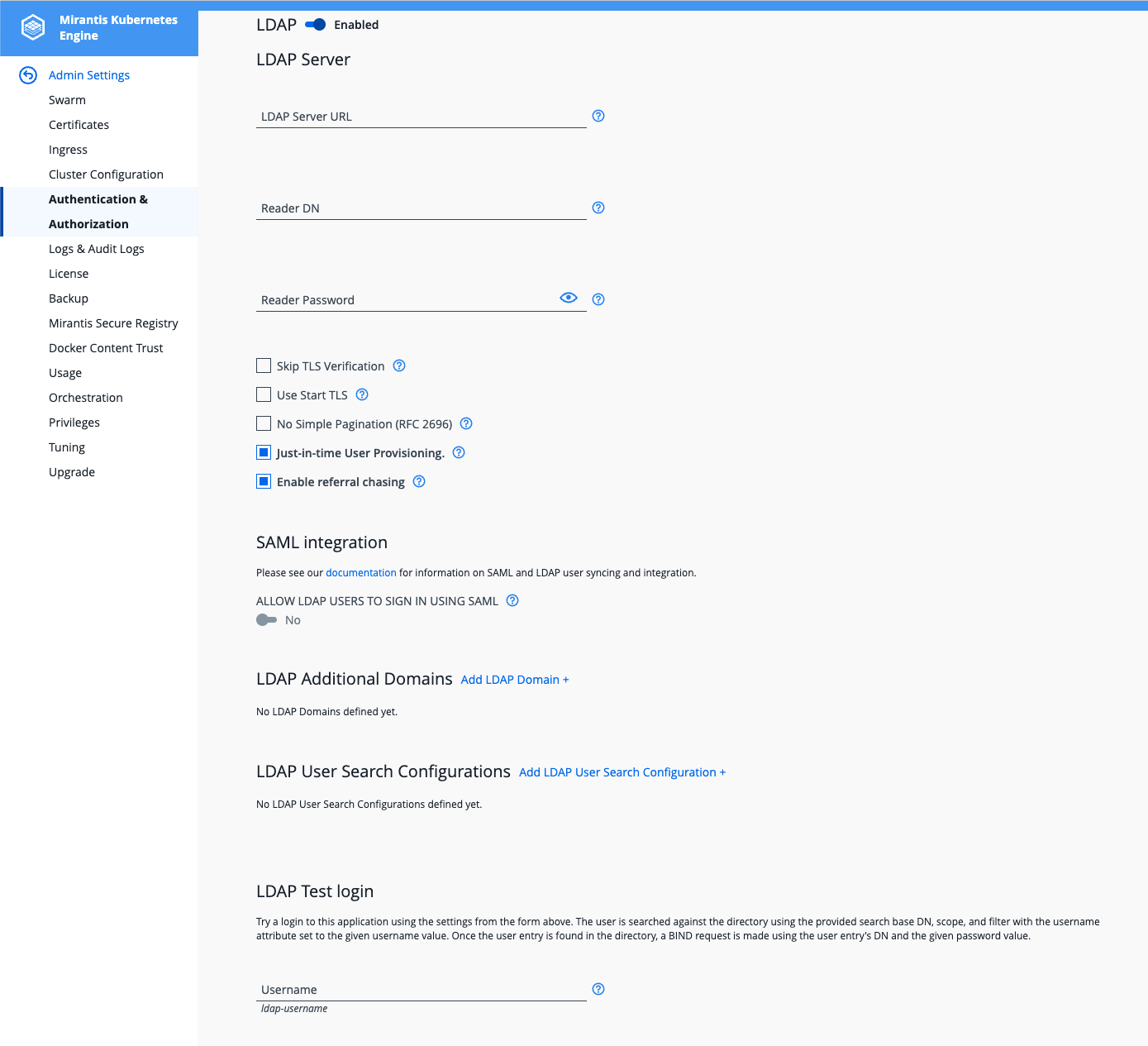
¶ Intégrer LDAP avec UCP (MKE)
Pour cela :
Admin→Admin Settings→Authentication & Authorization→LDAP enabledYES
Puis entrer les informations nécessaire à la connexion au LDAP :
¶ Linux namespaces
Docker utilise une technologie appelée “namespace” pour fournir un espace de travail isolé appelé conteneur.
Ces namespaces fournissent une couche d'isolation. Chaque aspect d'un conteneur s'exécute dans un namespace distinct et son accès est limité à cet "espace de noms".
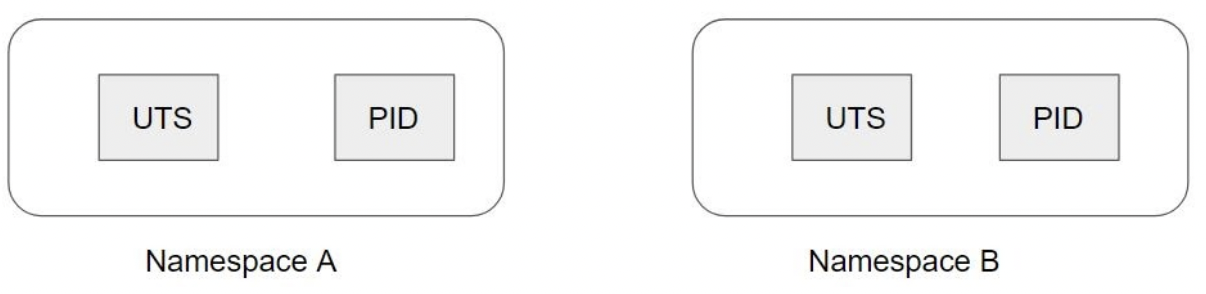
Actuellement, Linux fournit six types différents d'espaces de noms comme suit :
- Process (pid) : Cet espace de noms isole la numérotation des identifiants de processus (PID). Chaque container aura sa CMD principale avec un PID de 1
- Inter-Process Communication (IPC) : Isolation des ressources de communication entre processus, telles que les files de messages, les sémaphores et les segments de mémoire partagée.
- Network (net) : Offre l'isolation des ressources réseau, comme les adresses IP, les tables de routage, les sockets, etc.
- User Id (user) : Isolation des identifiants d'utilisateurs et de groupes. Dans cet espace de noms, un processus peut avoir une UID de 0 (root) mais peut être un UID non privilégié à l'extérieur de l'espace de noms.
- Mount (mnt) : Isolation des points de montage. Les processus dans cet espace de noms peuvent avoir une vue différente du système de fichiers par rapport à d'autres espaces de noms.
- UTS (Unix Time-sharing System) : Offre l'isolation des noms d'hôte et de domaine NIS (Network Information Services).
Les process (PID) sur l’hôte ne seront pas visibles par le container grâce à ce namespace.
- ps -ef dans un container n'affiche donc que les process du container.
- par contre si l’on fait un ps -ef sur l’hote, on verra bien les process du container avec un PID différent
- Un container a son propre namespace
¶ Control groups (cgroups)
Les groupes de contrôle (cgroups) sont une fonctionnalité du noyau Linux qui limite, comptabilise et isole l'utilisation des ressources (CPU, mémoire, E/S disque, réseau, etc.) d'un ensemble de processus.
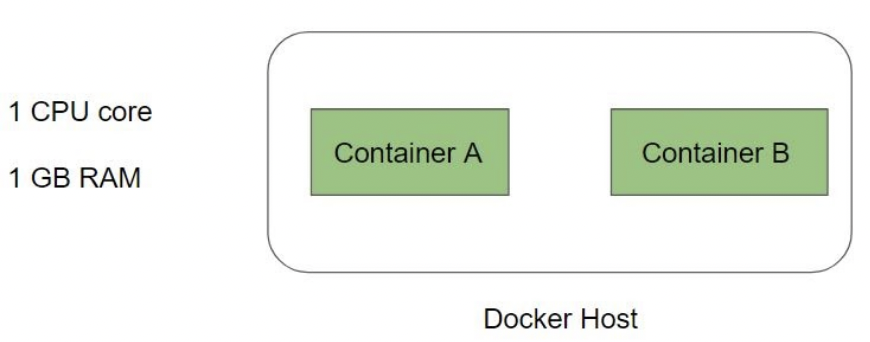
Ici l’hote à 1 CPU, 1go RAM. Les deux containers n’ont aucune limite pour le moment et tout se passe bien.
Cependant si le container A se fait attaquer (par exemple), il prendra donc toutes les ressources ! Le container B tournera donc moins bien.
On peut donc limiter l'utilisation CPU / RAM etc... de chaque container grace aux cgroups :
(source : Docker)
¶ Limiter la RAM pour un container
docker container run -it --name mymemory -m 256m busybox sh
docker exec -it mymemory sh
si on fait un free -m pour voir la quantité de mémoire du container, cela va prendre la quantité de RAM de l’hôte ! Car free ne prend pas en compte cgroup.
Pour voir la vraie quantité de RAM d’un container :
/ # cat /sys/fs/cgroup/memory/memory.limit_in_bytes
268435456
- 1 méga-octet = 1 048 576 Bytes
- 256m = 268 435 456 Bytes
¶ Limiter le CPU pour un container
On va limiter à 1,5 CPU dans un premier temps
Puis on va limiter à 2 CPU grâce à cpuset (0 et 1 = 2 CPUs)
docker container run -d --name constraint01 --cpus=1.5 busybox sh
docker container run -d --name constraint02 --cpuset-cpus=0,1 busybox sh
On peut voir le nombre de CPU sur notre machine via :
docker info
¶ Reservation vs Limits
- Reservation = --memory-reservation : c’est un peu du soft limit (équivalent à
requestde kubernetes). La valeur doit toujours être inférieur à -m - Limits = -m : Montant maximum associé au container. le container ne peut pas prendre plus de mémoire !
docker container run -d --name mywebserver -m 1G --memory-reservation 750M nginx
Dans l'exemple ci-dessus, nous avons fixé une limite de mémoire dure de 1GB et réservé 750 Megabyte. NGINX peut utiliser les 750 mégaoctets et augmenter la capacité jusqu'à la limite de 1 Go si nécessaire. Notez que la réservation est toujours plus petite que la limite.
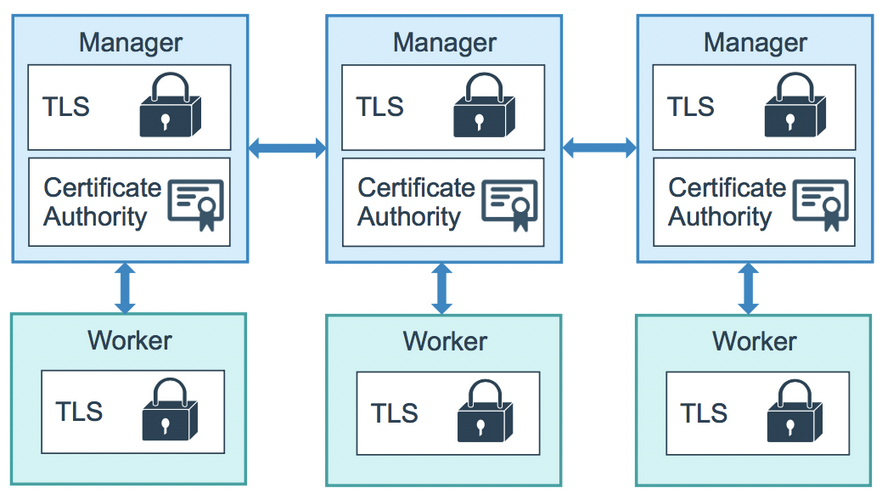
¶ Swarm MTLS
Les noeuds d'un swarm utilisent le protocole TLS (Transport Layer Security) mutuel pour authentifier, autoriser et chiffrer les communications avec les autres nœuds du swarm.
Par défaut, le nœud manager génère une nouvelle autorité de certification (CA) ainsi qu'une paire de clés, qui est utilisée pour sécuriser les communications avec les autres nœuds qui rejoignent le swarm.
Vous pouvez spécifier votre propre autorité de certification racine générée en externe, en utilisant l'indicateur --external-ca de la commande docker swarm init.
Chaque fois qu'un nouveau noeud rejoint le swarm, le gestionnaire émet un certificat pour le noeud.
Un réseau peut être chiffré via la commande --opt encrypted :
docker network create --opt encrypted --driver overlay
¶ Aperçu des join-tokens
Le noeud manager génère également deux jetons à utiliser lorsque vous joignez des nœuds supplémentaires au swarm : un token pour les workers et un token pour les managers.
Chaque token comprend le condensé du certificat de l'autorité de certification et un secret généré de façon aléatoire.
Lorsqu'un noeud rejoint le swarm, il utilise le “condensé” pour valider le certificat de l'autorité de certification racine du gestionnaire distant.
¶ Regénérer le certificat (CA)
Exécutez docker swarm ca --rotate pour générer un nouveau certificat et une nouvelle clé d'autorité de certification.
Dans la commande ci-dessus, le docker a généré un certificat à signature signé par l'ancienne CA précédente.
Une fois que chaque nœud du swarm dispose d'un nouveau certificat TLS signé par la nouvelle autorité de certification, Docker oublie l'ancien certificat et l'ancienne clé de l'autorité de certification et demande à tous les nœuds de faire confiance uniquement au nouveau certificat de l'autorité de certification.
Les tokens de connexion sont également modifiés en conséquence.
Le certificat se trouve :
$ cd /var/lib/docker/swarm/certificates
$ ls -l
total 12
-rw-r--r-- 1 root root 826 Mar 28 10:44 swarm-node.crt
-rw------- 1 root root 317 Mar 28 10:44 swarm-node.key
-rw-r--r-- 1 root root 550 Mar 28 10:44 swarm-root-ca.crt
Comme dit plus haut le token va donc aussi être renouvelé. Pour avoir le nouveau token :
docker swarm join-token worker
docker swarm join-token manager
¶ Détail du certificat
Par défaut, chaque nœud du swarm renouvelle son certificat tous les trois mois.
On peut configurer cet intervalle en exécutant la commande :
docker swarm update --cert-expiry <time_period> # Validity period for node certificates (ns|us|ms|s|m|h) (default 2160h0m0s)
Dans le cas où une clé d'autorité de certification de cluster ou un noeud manager est compromis, vous pouvez regénérer l'autorité de certification du swarm afin qu'aucun des noeuds ne fasse plus confiance aux certificats signés par l'ancienne autorité de certification.
¶ Gérer les secrets avec Docker Swarm
Les "secrets" Docker (Docker Swarm uniquement) permettent de gérer ces données de manière centralisée et de les transmettre en toute sécurité aux seuls conteneurs qui doivent y avoir accès.
Les "secrets" sont chiffrés pendant le transit et reposent dans un swarm Docker.
Un secret donné n'est accessible qu'aux services qui ont reçu un accès explicite à ce secret, et uniquement lorsque ces tâches de service sont en cours d'exécution.
$ docker secret ls
$ vim db_creds.txt
username: admin
pass: toto123
$ docker secret create dbcreds db_creds.txt
qf7wp54bdu0bs6mj0o9e27uvu
$ docker secret ls
ID NAME DRIVER CREATED UPDATED
qf7wp54bdu0bs6mj0o9e27uvu dbcreds 10 seconds ago 10 seconds ago
Une fois créé il faut maintenant pouvoir l’utiliser dans un container :
$ docker service create --name webserver --secret dbcreds nginx
On va donc maintenant trouver ou sont les secrets :
$ docker exec -it 630d190b79f6 bash
root@630d190b79f6:/$ cd /run/secrets/
root@630d190b79f6:/run/secrets$ cat dbcreds
username: admin
pass: toto123
¶ Docker Content Trust (déprécié/enlevé depuis Août 2025) :
Lorsque l’on télécharge des images à partir du réseau ou d'Internet, l'intégrité devient une véritable préoccupation.
La confiance dans le contenu vous donne la possibilité de vérifier à la fois l'intégrité et l'éditeur de toutes les données reçues d'un registre sur n'importe quel canal.
Ceci peut être réalisé à l'aide de signatures numériques.
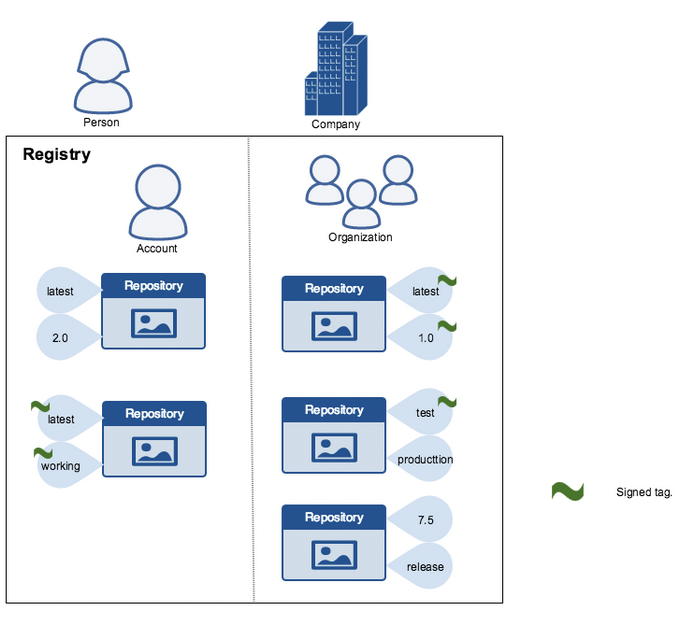
On peut mettre en place un paramètre qui n’accepte que les contenus signés !
Si on veut activer le DCT (Docker Content Trust) :
export DOCKER_CONTENT_TRUST=1
Si on essaie de pull une image non signée :
$ docker pull owncloudci/nodejs:latest
Error: remote trust data does not exist for docker.io/owncloudci/nodejs: notary.docker.io does not have trust data for docker.io/owncloudci/nodejs
On peut inspecter la signature d’une image :
$ docker trust inspect nginx
[
{
"Name": "nginx",
"SignedTags": [
{
"SignedTag": "1",
"Digest": "104c7c5c54f2685f0f46f3be607ce60da7085da3eaa5ad22d3d9f01594295e9c",
"Signers": [
"Repo Admin"
]
},
...
¶ Signer une image :
On va générer une clé qui nous servira à signer une image :
$ cd ~/
$ docker trust key generate <username>
Ajouter un “signer” au repo :
$ docker trust signer add --key <key file>.pub <username> <repo>
$ docker login
...
Login Succeeded
$ docker trust signer add --key antoine.pub achichi13 achichi13/test-repo
Adding signer "achichi13" to achichi13/test-repo...
Initializing signed repository for achichi13/test-repo...
Enter passphrase for root key with ID 74deb81:
Enter passphrase for new repository key with ID da91fdb:
Repeat passphrase for new repository key with ID da91fdb:
Successfully initialized "achichi13/test-repo"
Successfully added signer: achichi13 to achichi13/test-repo
On va maintenant créer une image afin de signer celle-ci :
$ mkdir ~/test-repo
$ cd test-repo/
$ vim Dockerfile
FROM busybox
CMD echo "hello"
On va maintenant build l’image sans signer :
$ docker build -t achichi13/test-repo:signed .
# On push sur docker hub avec notre user achichi
$ docker push achichi13/test-repo:signed
The push refers to repository [docker.io/achichi13/test-repo]
3d24ee258efc: Mounted from library/busybox
unsigned: digest: sha256:28fd8f6e9ef32aefde5f7da9cf5383b4c5f92e049fa9908e18562c5ddac6cf14 size: 527
Signing and pushing trust metadata
Enter passphrase for antoine key with ID b0bc84d:
Successfully signed docker.io/achichi13/test-repo:signed
On va maintenant signer une nouvelle image qui appartient à un repo qui n'a pas ma clé :
$ docker build -t achichi13/manual-sign:signed .
$ docker trust sign achichi13/manual-sign:signed
Created signer: achichi13
Finished initializing signed repository for achichi13/manual-sign:signed
Signing and pushing trust data for local image achichi13/manual-sign:signed, may overwrite remote trust data
The push refers to repository [docker.io/achichi13/manual-sign]
3d24ee258efc: Mounted from achichi13/test-repo
signed: digest: sha256:28fd8f6e9ef32aefde5f7da9cf5383b4c5f92e049fa9908e18562c5ddac6cf14 size: 527
Signing and pushing trust metadata
...
Successfully signed docker.io/achichi13/manual-sign:signed
Cette commande va signer et push l’image sur Docker Hub. On peut maintenant lancer le container avec le paramètre export DOCKER_CONTENT_TRUST=1.
¶ Aperçu du Docker group Linux
Par défaut, uniquement l’utilisateur root peut lancer des commandes docker. Les autres devront avoir les droits sudo pour exécuter des commandes.
Voici un exemple (ne fonctionne pas sur play-with-docker), on ajoute un utilisateur et on teste une commande docker :
$ adduser antoine
$ su - antoine
manager1:~$ id
uid=1000(antoine) gid=1000(antoine) groups=1000(antoine)
manager1:~$ docker container ls
Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.sock: Get http://%2Fvar%2Frun%2Fdocker.sock/v1.24/containers/json: dial unix /var/run/docker.sock: connect: permission denied
On va maintenant ajouter antoine au groupe docker afin de l'autoriser à exécuter des commandes docker sans sudo :
$ usermod -aG docker antoine
# OU
$ vim /etc/group
# ajouter l'user à côté du groupe Docker
Une fois fait :
$ su antoine
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
Attention : faire cela uniquement avec des utilisateurs de confiance. Ils pourraient exécuter des container en mode privilégié et donc accéder à tous les fichiers sur le système.
¶ Linux capabilities
Il existe plusieurs types de “capabilities” que Linux fournit pour avoir un accès granulaire au niveau de l'application.
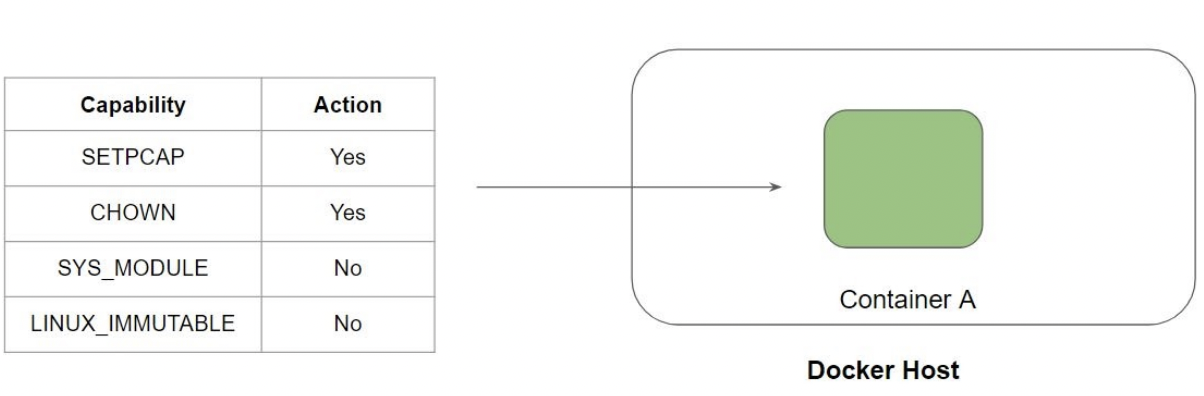
On voit donc que le container n’aura pas le droit de créer un fichier immuable (chattr +i test.txt).
- chattr = changer les attributs d'un fichier
On peut retrouver la liste des capabilities Docker run reference | Docker Documentation :
--cap-add--cap-drop--privileged
$ docker container run -it --rm --name cap1 --cap-add LINUX_IMMUTABLE ubuntu bash
$ touch test.txt
# Rendre le fichier immuable
$ chattr +i test.txt
$ vim test.txt
-- INSERT -- W10: Warning: Changing a readonly file
Avant de quitter le container, bien remettre le fichier modifiable, sinon le container ne pourra pas être détruit car le fichier test.txt est immuable 
$ chattr -i test.txt
Sans ce --cap-add :
$ docker container run -it --rm --name cap2 ubuntu bash
$ touch test.txt
$ chattr +i test.txt
chattr: Operation not permitted while setting flags on test.txt
De manière général, aucune capabilities supplémentaire n'est nécessaire. Il est même recommandé de --cap-drop toutes les capabilities :
$ docker container run -it --rm --name cap2 --cap-drop all ubuntu bash
¶ Container "privileged"
¶ Comprendre le Challenge
Par défaut, le conteneur Docker n'a pas beaucoup de capacités qui lui sont attribuées.
- Les conteneurs Docker ne sont pas non plus autorisés à accéder à des périphériques.
Par conséquent, par défaut, le conteneur Docker ne peut pas réaliser divers cas d'utilisation comme exécuter un conteneur Docker à l'intérieur d'un conteneur Docker.
¶ Containers "Privileged"
Les conteneurs privilégiés peuvent accéder à tous les périphériques de l'hôte et ont une configuration dans AppArmor ou SELinux pour permettre au conteneur d'avoir presque tous les mêmes accès à l'hôte que les processus s'exécutant en dehors des conteneurs sur l'hôte :
- Les limites que vous définissez pour les conteneurs privilégiés ne seront pas respectées.
- L'exécution d'un container privilégié donne toutes les capacités au conteneur.
⚠️ DANGER :
--privilegeddonne accès TOTAL à l'hôte et à ses périphériques !Un conteneur lancé avec
--privilegedpeut :
- Accéder à tous les périphériques de l'hôte (
/dev/*incluant les disques durs)- Monter le système de fichiers de l'hôte et le modifier
- Charger des modules kernel sur l'hôte
- Désactiver les mécanismes de sécurité (SELinux, AppArmor)
- S'échapper du conteneur et prendre le contrôle de l'hôte
- Accéder à la mémoire d'autres processus et conteneurs
- Modifier les paramètres réseau de l'hôte
¶ Risques concrets du mode privileged
1. Évasion du conteneur (Container Escape)
Un attaquant dans un conteneur privileged peut facilement s'échapper et obtenir un accès root sur l'hôte :
# Depuis le conteneur privileged, monter le disque de l'hôte
$ mount /dev/sda1 /mnt
# Accéder au système de fichiers de l'hôte
$ chroot /mnt
# Vous êtes maintenant root sur l'hôte !
2. Accès aux données sensibles
- Lecture de tous les fichiers de l'hôte (
/etc/shadow, clés SSH, secrets) - Accès aux données des autres conteneurs
- Lecture de la mémoire RAM contenant des mots de passe en clair
3. Modification du kernel
# Charger un module kernel malveillant
$ insmod malicious_module.ko
# Modifier les paramètres système critiques
$ echo 0 > /proc/sys/kernel/modules_disabled
4. Attaque sur le réseau
- Sniffing du trafic réseau de l'hôte et des autres conteneurs
- Modification des règles iptables
- Man-in-the-middle sur les communications
¶ Alternatives sécurisées à --privileged
Au lieu d'utiliser --privileged, utilisez des permissions granulaires :
1. Capabilities spécifiques
# Au lieu de --privileged, utilisez uniquement les capabilities nécessaires
$ docker run --cap-add SYS_ADMIN nginx
$ docker run --cap-add NET_ADMIN nginx
2. Montage de devices spécifiques
# Monter uniquement le device nécessaire
$ docker run --device /dev/fuse nginx
3. Options de sécurité ciblées
# Désactiver uniquement les protections nécessaires
$ docker run --security-opt apparmor=unconfined nginx
$ docker run --security-opt seccomp=unconfined nginx
4. Montage de volumes spécifiques
# Monter uniquement les répertoires nécessaires
$ docker run -v /sys/fs/cgroup:/sys/fs/cgroup:ro nginx
Pour exécuter un container en privileged :
$ docker run -itd --privileged --name nginx_priv nginx
N'utilisez JAMAIS
--privilegeden production !Il est très rare de devoir avoir besoin de
--privileged. Les cas légitimes sont :
- Docker-in-Docker pour les pipelines CI/CD (utilisez plutôt Docker socket mounting)
- Debugging système très spécifique (uniquement en environnement isolé)
- Émulation de systèmes (utilisez des VMs à la place)