¶ Orchestration
¶ Vue d'ensemble de l'orchestration de containers :
L’utilité de l’orchestration :
- Provisionning et déploiement des containers
- Scaling (up / down) des containers pour répartir la charge de manière équilibré
- Bouger un ou plusieurs container d’un noeud à un autre
- Load Balancing
- Superviser la santé des containers
Il existe plusieurs solutions pour orchestrer des containers :
- Docker Swarm
- Kubernetes
- Apache Mesos
- Elastic Container Service (AWS ECS)
¶ Aperçu de Docker Swarm & Labs :
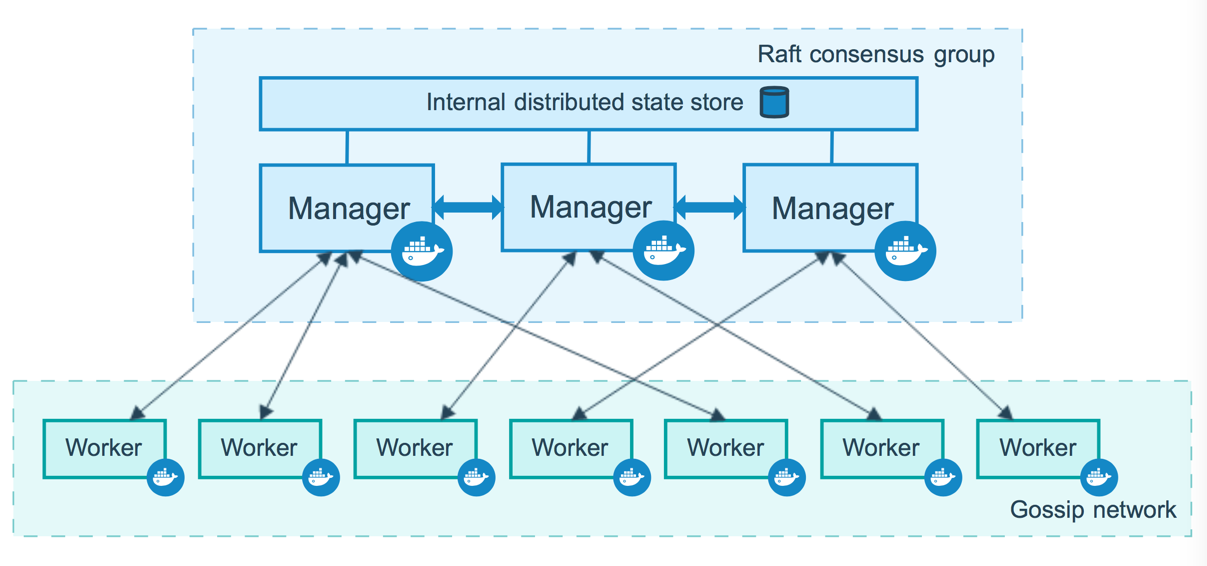
Docker Swarm est un outil de gestion de clusters pour Docker. Il transforme un groupe d'hote avec Docker, en un seul cluster Docker virtuel.
Docker Swarm est essentiellement un outil de gestion de clusters pour Docker. Imaginez pouvoir combiner plusieurs moteurs Docker en une seule entité. C'est exactement ce que Swarm permet. Avec cet outil, non seulement vous pouvez orchestrer et déployer des conteneurs sur plusieurs hôtes Docker, mais vous pouvez aussi gérer facilement la mise à l'échelle des conteneurs et assurer leur haute disponibilité.
L'une des forces de Swarm réside dans sa capacité à découvrir dynamiquement les nœuds. Cela signifie que les moteurs Docker, ou nœuds, peuvent être facilement ajoutés ou retirés du cluster. Et pour garantir que les applications répondent rapidement, Swarm intègre également un équilibrage de charge natif pour répartir les requêtes entre les conteneurs d'un service. De plus, si un conteneur échoue pour une raison quelconque, Swarm veille à le remplacer, garantissant ainsi une redondance et une disponibilité élevées.
D'un point de vue architectural, Docker Swarm est structuré autour de deux types de nœuds : les Manager Nodes et les Worker Nodes. Les premiers sont le cerveau de l'opération. Ils prennent toutes les décisions importantes d'orchestration, que ce soit pour créer ou mettre à l'échelle des services. Ils sont aussi responsables de la distribution des tâches aux Worker Nodes, qui, comme leur nom l'indique, font tout le travail réel en exécutant les conteneurs.
Une particularité intéressante de Swarm est sa notion de services et de tâches. Un service est essentiellement ce que vous souhaitez obtenir comme état final, par exemple, avoir trois instances d'une application en cours d'exécution. Une tâche, quant à elle, est une unité de travail assignée par Swarm, qui se manifeste souvent comme un conteneur en cours d'exécution.
L'intégration étroite avec Docker est sans doute l'un des plus grands avantages de Swarm. Vous pouvez interagir avec lui en utilisant la même ligne de commande Docker.
(source: docs docker)
Les ports suivants doivent être disponibles pour créer le cluster Swarm. Sur certains systèmes, ces ports sont ouverts par défaut :
- Port 2377 TCP pour la communication avec et entre les nœuds du gestionnaire
- Port 7946 TCP/UDP pour la découverte des nœuds du réseau superposé
- Port 4789 UDP (configurable) pour le trafic du réseau superposé
- Si vous prévoyez de créer un réseau overlay avec chiffrement (
--opt encrypted), vous devez également vous assurer que le trafic du protocole IP 50 (IPSec ESP) est autorisé.
On peut s'entrainer gratuitement (grâce à un compte docker) via le site "Play With Docker" : https://labs.play-with-docker.com/
¶ Initialisation d'un cluster Docker Swarm :
Un noeud = 1 machine avec docker installé dessus qui a rejoint le cluster.
Pour déployer une application vers swarm il faut envoyer une définition de service à un noeud Swarm dit “Manager”
Le noeud manager dispatche ensuite le “travail” vers les workers.
Pratique :
# Initialisation du cluster swarm :
docker swarm init --advertise-addr 192.168.0.28 # ou 192.168.0.28 est l’IP de la machine
# Sur les machines workers, entrer la commande suivante avec le token récupéré grâce à la première commande :
docker swarm join --token SWMTKN-1-4q8s27rk2r19y71yyg7kzzuxngimtyt4w9mwkm4oiioh7r1jjx-80017fi6gu7cicufm4hd0ev5d 192.168.0.28:2377
Si on veut joindre en tant que manager, on va afficher le token via la commande suivante :
docker swarm join-token manager
Puis entrer la commande qui est affiché pour ajouter un/plusieurs manager.
Pour lister les nodes :
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
i7nks069qd0n1nzrph5rkibgo * node1 Ready Active Reachable 24.0.2
ifsymu0oozdrfp43qupkvjr8v node2 Ready Active Reachable 24.0.2
yxo7ql1obqpnv8mh1wwv7v1b0 node3 Ready Active Leader 24.0.2
¶ Services, Tasks, Containers :
Pour docker swarm, un service est la tâche à remplir pour le manager ou les workers.
Pour lancer un service nginx, on peut lancer la commande suivante (sur un manager uniquement) :
$ docker service create --name webserver --replicas 1 nginx
0j4v5i87npgpz7kin7s0az9co
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
Une fois exécuté, on peut lister les services en cours :
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
0j4v5i87npgp webserver replicated 1/1 nginx:latest
Pour avoir plus de détail sur un service précis :
$ docker service ps webserver
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
xfccps3gh9k2 webserver.1 nginx:latest node3 Running Running 19 seconds ago
Ici, on peut voir que le service webserver exécute la "task" webserver.1 sur le noeud node3.
Si on stoppe le container (et non le service) sur le noeud (ici node3) et que l’on refait un docker service ps webserver nous allons voir l’historique du service soit :
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5931ebad7f0f nginx:latest "/docker-entrypoint.…" About a minute ago Up About a minute 80/tcp webserver.1.xfccps3gh9k2e0d8qxbu2yoxu
$ docker stop 5931
5931
$ docker service ps webserver
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
ji2u2a8egz3n webserver.1 nginx:latest node2 Running Running 30 seconds ago
xfccps3gh9k2 \_ webserver.1 nginx:latest node3 Shutdown Complete 36 seconds ago
On voit que le container est passé du node3 au node2 automatiquement. Le service a relancé le container sur un autre noeud.
Pour supprimer un service il faut faire la commande :
docker service rm webserver
¶ Mise à l'échelle (scale) un service avec swarm :
Une fois qu’on a un service déployé sur swarm on peut vouloir plusieurs instances de ce service. On va donc scaler le service :
$ docker service scale webserver=5
webserver scaled to 5
overall progress: 2 out of 5 tasks
1/5: running [==================================================>]
2/5: preparing [=================================> ]
3/5: running [==================================================>]
4/5: preparing [=================================> ]
5/5: preparing [=================================> ]
Cela va donc déployer 5 instances de webserver (nginx) :
$ docker service ps webserver
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
lsxdc8etinkd webserver.1 nginx:latest node3 Running Running 36 seconds ago
617c0gmpwzy3 webserver.2 nginx:latest node1 Running Running 10 seconds ago
zj5my7sakaeo webserver.3 nginx:latest node3 Running Running 17 seconds ago
773ehn81q5gs webserver.4 nginx:latest node2 Running Running 11 seconds ago
nt41u1d03e7x webserver.5 nginx:latest node1 Running Running 10 seconds ago
En faisant un docker container ps sur le node1 on verra donc 2 containers tourner :
[node1] (local) root@192.168.0.13 ~
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5e3d59dc9e75 nginx:latest "/docker-entrypoint.…" 33 seconds ago Up 32 seconds 80/tcp webserver.5.nt41u1d03e7xd4djbge6m621a
ef00e496818f nginx:latest "/docker-entrypoint.…" 33 seconds ago Up 32 seconds 80/tcp webserver.2.617c0gmpwzy3fsxbzllfujibw
¶ Multiple approche pour scaler :
On a 2 moyens de scaler un service dans docker swarm :
docker service scale webserver=5
docker service update --replicas 5 webserver
La commande avec scale peut prendre plusieurs services :
docker service scale webserver=5 webserver2=5
Ce n’est pas possible avec la commande update
¶ Replicated vs Global Service :
Il y a 2 types de déploiement : Répliqué / Global
Pour un déploiement répliqué on va préciser le nombre de “tâches” que l’on veut lancer, exemple avec nginx : --replicas 5 nginx.
Un déploiement global va lancer une tâche sur chaque noeud. Si on augmente notre cluster d’un noeud alors l’orchestrateur va créer une nouvelle tâche et le scheduler va assigner cette tâche au nouveau noeud.
Pour lancer un déploiement global :
docker service create -dt --name global --mode global ubuntu:latest
En faisant un docker service ps global on voit donc que le déploiement est sur nos X noeuds :
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
lsdjif1fdvwf global global 3/3 ubuntu:latest
$ docker service ps global
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
ohngyv5qwcx3 global.i7nks069qd0n1nzrph5rkibgo ubuntu:latest node1 Running Running 23 seconds ago
5vnpqqelrowt global.ifsymu0oozdrfp43qupkvjr8v ubuntu:latest node2 Running Running 23 seconds ago
q2hxud4eaoha global.yxo7ql1obqpnv8mh1wwv7v1b0 ubuntu:latest node3 Running Running 22 seconds ago
¶ Drain un noeud swarm :
Cela peut arriver de vouloir redémarrer un noeud, de faire des updates…
Il va donc falloir sortir le noeud du cluster proprement afin que les tâches soient envoyées sur un autre noeud. On va donc exécuter les commandes suivantes (toujours sur le master) :
[node1] (local) root@192.168.0.13 ~
$ docker node update --availability drain node1
node1
[node1] (local) root@192.168.0.13 ~
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
Puis on va vérifier que le noeud est bien en mode "drain" :
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
i7nks069qd0n1nzrph5rkibgo * node1 Ready Drain Reachable 24.0.2
ifsymu0oozdrfp43qupkvjr8v node2 Ready Active Reachable 24.0.2
yxo7ql1obqpnv8mh1wwv7v1b0 node3 Ready Active Leader 24.0.2
Si on regarde docker service ps webserver on va alors voir que les tâches sur node1 ont été bougé sur un autre noeud :
$ docker service ps webserver
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
lsxdc8etinkd webserver.1 nginx:latest node3 Running Running 5 minutes ago
s2rkle0n0ryf webserver.2 nginx:latest node2 Running Running 2 minutes ago
617c0gmpwzy3 \_ webserver.2 nginx:latest node1 Shutdown Shutdown 2 minutes ago
zj5my7sakaeo webserver.3 nginx:latest node3 Running Running 5 minutes ago
773ehn81q5gs webserver.4 nginx:latest node2 Running Running 5 minutes ago
zjym7k3tfk61 webserver.5 nginx:latest node2 Running Running 2 minutes ago
nt41u1d03e7x \_ webserver.5 nginx:latest node1 Shutdown Shutdown 2 minutes ago
Une fois la mise à jour effectuée on peut remettre le noeud en actif :
docker node update --availability active node1
¶ Inspect : Services swarm & Noeuds
Docker inspect donne des informations détaillées sur les “docker objects” :
- docker container
- docker network
- docker volume
- docker service
- docker node
Pour inspecter un service docker :
$ docker service inspect webserver
[
{
"ID": "j6zxusdm6cxj836qopalctb5m",
"Version": {
"Index": 62
},
"CreatedAt": "2023-08-22T12:46:49.481961443Z",
...
# Pour un output plus jolie mais avec moins d'infos :
$ docker service inspect webserver --pretty
ID: j6zxusdm6cxj836qopalctb5m
Name: webserver
Service Mode: Replicated
Replicas: 5
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: nginx:latest@sha256:104c7c5c54f2685f0f46f3be607ce60da7085da3eaa5ad22d3d9f01594295e9c
Init: false
Resources:
Endpoint Mode: vip
On peut aussi inspecter le node :
docker node ls
# docker node inspect <id> --pretty
$ docker node inspect node1 --pretty
ID: i7nks069qd0n1nzrph5rkibgo
Hostname: node1
Joined at: 2023-08-22 12:41:52.568766627 +0000 utc
Status:
State: Ready
Availability: Active
Address: 192.168.0.13
Manager Status:
Address: 192.168.0.13:2377
Raft Status: Reachable
Leader: No
...
¶ Ajout d'un réseau et publication d'un port
Actuellement nginx n’est pas joignable car le port n’est pas “publié”. On sait publier un port sur docker via -p 80:80. Comment faire via docker swarm ?
docker service create --name mywebserver --replicas 2 --publish 8080:80 nginx:latest
ou --publish peut être aussi -p
On peut aussi mettre à jour un service existant :
docker service update --publish-add 8081:80 webserver
¶ Aperçu de Docker compose :
Docker Compose est un outil qui permet de lancer une application docker multi-container (web + bdd par exemple)
- Docker compose utilise le format YAML pour configurer l’application.
- On peut démarrer tous les container avec une seule commande : docker-compose up
- De même pour éteindre tous les containers : docker-compose down
Voici un exemple de configuration Wordpress via docker-compose :
version: "3.8"
services:
db:
image: mysql:8.0
volumes:
- db_data:/var/lib/mysql
environment:
MYSQL_ROOT_PASSWORD: somewordpress
MYSQL_DATABASE: wordpress
MYSQL_USER: wordpress
MYSQL_PASSWORD: wordpress
wordpress:
depends_on:
- db
image: wordpress:php8.2
volumes:
- wordpress_data:/var/www/html
ports:
- "8000:80"
deploy:
replicas: 2
environment:
WORDPRESS_DB_HOST: db:3306
WORDPRESS_DB_USER: wordpress
WORDPRESS_DB_PASSWORD: wordpress
WORDPRESS_DB_NAME: wordpress
volumes:
db_data:
name: db-data
wordpress_data:
name: wordpress-data
Docker-compose fonctionne à partir de la version 2, la version 1 de docker-compose est dépréciée.
Pour vérifier que le fichier de config est bon :
docker-compose config
On peut ensuite démarrer les 2 containers via la commande : docker-compose up -d
- -d pour detached : exécutera en background
Cependant, cela va déployer mysql et wordpress sur le même noeud ! Ce n'est donc pas adapté à Docker Swarm. Pour déployer un docker-compose sur plusieurs noeuds il faut utiliser docker stack deploy.
Attention, si vous voulez que votra application soit 100% HA, il faut que votre volume soit partagé entre les noeuds (NFS / GlusterFS...)
Une stack est un groupe de services interconnectés entre eux qui ont des dépendances et peuvent être orchestré/scale ensemble.
Un fichier stack compose est en YAML et est du même format que le docker-compose (et fonctionne de la même manière, à quelques commandes prêts). Le fichier stack compose fonctionne qu'à partir de la version 3
On va donc déployer Wordpress sur le swarm :
$ docker stack deploy mywordpress --compose-file compose.yml
Creating network mywordpress_default
Creating service mywordpress_db
Creating service mywordpress_wordpress
On va ensuite regarder l’état du déploiement :
$ docker stack ps mywordpress
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
uyh0bjk01of0 mywordpress_db.1 mysql:5.7 node3 Running Running 12 seconds ago
sscq6qfzaab2 mywordpress_wordpress.1 wordpress:latest node2 Running Running 11 seconds ago
Lister les stacks :
$ docker stack ls
NAME SERVICES
mywordpress 2
Lister les services associés à la stack :
$ docker stack services mywordpress
ID NAME MODE REPLICAS IMAGE PORTS
fpt14kua8112 mywordpress_db replicated 1/1 mysql:5.7
9qe6xdazlohu mywordpress_wordpress replicated 1/1 wordpress:latest *:8000->80/tcp
Pour supprimer la stack :
docker stack rm mywordpress
¶ Verrouiller le cluster Swarm :
Le cluster Swarm contient des données sensibles qui incluent :
- Clé TLS pour chiffrer les communications entre les noeuds
- La clé utilisé pour chiffrer/déchiffrer les logs Raft sur le disque (Raft est le protocole pour avoir un “consensus distribué” : Explication très intéressante ici : Raft (thesecretlivesofdata.com)
Si le cluster swarm est compromis et que les données sont stockées en claires… L’attaquant aura donc toutes les données.
Docker autolock nous autorise à avoir le contrôle sur ces clés.
$ ls -al /var/lib/docker/swarm/certificates/
total 12
drwxr-xr-x 2 root root 75 Aug 22 12:41 .
drwx------ 5 root root 95 Aug 22 12:41 ..
-rw-r--r-- 1 root root 826 Aug 22 12:41 swarm-node.crt
-rw------- 1 root root 317 Aug 22 12:41 swarm-node.key
-rw-r--r-- 1 root root 554 Aug 22 12:41 swarm-root-ca.crt
$ cat swarm-node.key
-----BEGIN PRIVATE KEY-----
kek-version: 239
raft-dek: EiAgvAdZvbBQyz99Gk387HYg8jz+yk1cOBlSXZOnltaYJw==
MIGHAgEAMBMGByqGSM49AgEGCCqGSM49AwEHBG0wawIBAQQg7Plurjz4POBNrWxJ
XRe7LdWDiO6UymOY6d8x+7yuGLuhRANCAARhyLaAq55FNzADmbQ+peMPe0nz1X6p
uVCvpFYui/8awvFRyvbr+Kv5c8IP4Yq/0vl+isLz8MWahhQwbo19dt6j
-----END PRIVATE KEY-----
Si on fait un cat sur la clé privée celle-ci va s'afficher. On voit que tout est stocké en plain-text, le hacker a donc accès à tout.
On va donc verrouiller le cluster afin de rajouter une sécurité :
$ docker swarm update --autolock=true
Swarm updated.
To unlock a swarm manager after it restarts, run the `docker swarm unlock`
command and provide the following key:
SWMKEY-1-oUQ0F8uWiVWj5BNk4coAagVyhMAqUtghSxvkYx7z8EU
...
# Bien garder la clé dans un endroit sécurisé puis redémarrer docker
systemctl restart docker
# Sur play-with-docker :
kill -9 `pgrep dockerd`; dockerd > /docker.log 2>&1 &
Le cluster est maintenant verrouillé, on ne peut plus exécuter de commande sans le déverrouiller.
$ docker node ls
Error response from daemon: Swarm is encrypted and needs to be unlocked before it can be used. Use "docker swarm unlock" to unlock it.
On peut voir aussi que la clé est chiffrée :
$ cat swarm-node.key
-----BEGIN ENCRYPTED PRIVATE KEY-----
kek-version: 240
raft-dek: CAESMNi5/oyitisYksjoUWQ4YPejaDYpQFRYUFB68ZRjV8mDl6ii2y9i53Lkz5Rg+yp4lBoY8fHt1TYdoUc9XWB3eA5YguihjM4w2gVE
MIHeMEkGCSqGSIb3DQEFDTA8MBsGCSqGSIb3DQEFDDAOBAhHX0bJBS7pIAICCAAw
HQYJYIZIAWUDBAEqBBD44p2KpUatif3C69PAuPVvBIGQPvztSQ8PZdNNAjDhXcHb
lndqHnHaK/hFTicxSfjhYC6hXQHZiuGMOID3wLlb5lpWSLxGR7YWF/AdUdKRiwZM
DzG70KE9kJPvbpqcRn37iY0hPb9C00koQDWoKPBWVJWn29HhKOUHQ0TSwkL5fjLM
mfO+UVJADTRGs6jCF65FxepiUmP+fK2Izj5ha9Zg7BJy
-----END ENCRYPTED PRIVATE KEY-----
On va déverrouiller le cluster afin de pouvoir entrer les commandes que nous voulons :
$ docker swarm unlock
Please enter unlock key:
On peut maintenant exécuter : docker node ls sans problème
On peut aussi retrouver notre clé de deverrouillage en faisant :
docker swarm unlock-key
On peut aussi changer la clé en forçant un rotate :
docker swarm unlock-key --rotate
¶ Déboguer un service Swarm
Un service peut être configuré de manière à ce que le noeud ne puisse pas exécuter sa tâche.
Il va donc être en statut pending
Il y a plusieurs raisons à cela :
- Si tous les noeuds sont en mode drain il va donc falloir attendre qu’au moins un noeud redevienne disponible
- On peut spécifier un certain montant de memory/cpu pour un service. Si aucun noeud n’a cette ressource, le service attendra un noeud avec la ressource nécessaire
- On a placé une contrainte qui ne peut pas être satisfaite
Imaginons le service suivant :
docker service create --name demotroubleshoot --constraint node.labels.region==marseille --replicas 3 nginx
Dans le cas ou on a un service en pending on va inspecter le service :
$ docker service ps demotroubleshoot
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
pb9r3v4xd1s3 demotroubleshoot.1 nginx:latest Running Pending 14 seconds ago "no suitable node (scheduling …"
bpw8wetrk2gt demotroubleshoot.2 nginx:latest Running Pending 14 seconds ago "no suitable node (scheduling …"
k1epqp50fkbv demotroubleshoot.3 nginx:latest Running Pending 14 seconds ago "no suitable node (scheduling …"
docker service inspect demotroubleshoot
Sur ce service on avait la contrainte suivante node.labels.region==marseille. Sauf que si l'on inspecte notre noeud, nous n'avons aucune constraint :
docker node inspect node2
...
"Spec": {
"Labels": {},
"Role": "manager",
"Availability": "active"
},
...
On peut ajouter ce label à un noeud via la commande :
$ docker node update --label-add region=marseille node2
docker node inspect node2
...
"Spec": {
"Labels": {
"region": "marseille"
},
"Role": "manager",
"Availability": "active"
},
...
Maintenant le service a pu être déployé, uniquement sur le node2 étant donné qu'il est le seul à avoir le label demandé.
¶ Monter un volume via Swarm :
docker service create --name myservice --mount type=volume,source=myvolume,target=/mypath nginx
# -v ne fonctionne pas pour un service
Dans notre cas on va donc créer un volume myvolume qui se trouvera dans /mypath du container.
$ docker volume ls
DRIVER VOLUME NAME
local myvolume
On peut retrouver ce volume sur la machine qui fait tourner le container :
$ ls /var/lib/docker/volumes/
backingFsBlockDev metadata.db myvolume
On voit le dossier myvolume qui contient toutes les données de /mypath du service myservice.
¶ Controler le placement du service :
Les services swarm donnent différentes manières pour nous de contrôler la scalabilité et le placement des services sur différents noeuds :
- Replicated et Global services
- Contrainte de ressources (Minimum de CPU/RAM)
- Contrainte de placement (lancer uniquement sur un noeud avec le label ssd=true)
- Préférence de placement
docker service create --name demotroubleshoot --constraint node.labels.region==lille --replicas 3 nginx
node.labels est constant. Region
est la clé, lille est la valeur.
Il va donc falloir ajouter le label region:lille à minimum un noeud !
Pour ajouter un label à un noeud :
docker node update --label-add region=lille node2
On peut aussi préférer que le déploiement soit fait équitablement en fonction des labels :
node-1: datacenter=us-east, disk=ssd
node-2: datacenter=us-east, disk=ssd
node-3: datacenter=us-west, disk=sas
node-4: datacenter=us-west, disk=nl-sas
On va donc demander de répartir équitablement sur les noeuds :
docker service create --replicas 2 --name webserver --placement-pref spread=node.labels.datacenter mywebservice:production
Cela va donc mettre le service webserver sur 2 noeuds différents : node-1 ou node-2 ainsi que node-3 ou node-4 afin de partager équitablement sur 2 labels différents !
¶ Réseau overlay :
Le driver “overlay network” fournit un réseau à tous les hôtes du cluster docker swarm.
Cela va créer une connexion sécurisée entre les containers.
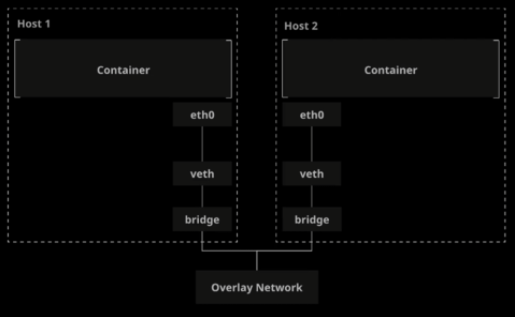
$ docker network ls
NETWORK ID NAME DRIVER SCOPE
05b51c5a4b09 bridge bridge local
1cdd723c0406 docker_gwbridge bridge local
a4f6d670297e host host local
ulhud9qe6kzl ingress overlay swarm
9dcecdb6d240 none null local
d7b786760ceb root_default bridge local
Un network overlay est créé par défaut lorsqu’on utilise swarm.
On peut regarder le réseau en détail :
$ docker network inspect ingress
...
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "10.0.0.0/24",
"Gateway": "10.0.0.1"
}
]
},
...
"Peers": [
{
"Name": "604f910b5637",
"IP": "192.168.0.11"
},
{
"Name": "9f4ecd59a6d4",
"IP": "192.168.0.12"
},
...
]
}
]
On va voir ici nos X noeuds du cluster.
Chaque container aura une IP privée pour le réseau overlay :
$ docker container inspect 61b7c8e83122
...
"Networks": {
"ingress": {
"IPAMConfig": {
"IPv4Address": "10.0.0.19"
},
"Links": null,
"Aliases": [
"32e73d31fecc"
],
"NetworkID": "ulhud9qe6kzlebo1h9uz09c32",
"EndpointID": "270f4ca42f9a0eb4d4677814c0f7f15dd5095d0c30a3e3b5c08f01d025c172d9",
"Gateway": "",
"IPAddress": "10.0.0.19",
"IPPrefixLen": 24,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:0a:00:00:13",
"DriverOpts": null
}
}
...
¶ Créer un nouveau réseau overlay
Création du network mynetwork (overlay) :
$ docker network create --driver overlay mynetwork
# Lancement d'un service sur le réseau mynetwork
$ docker service create --name myoverlay --network mynetwork --replicas 3 nginx
Vérification du network :
docker network ls
Trouver l’IP du container :
docker container inspect [CONTAINER-NAME]
¶ Sécuriser le réseau overlay
Il est recommandé de chiffrer les échanges dans le réseau overlay. Pour se faire nous allons utiliser le paramètre --opt :
docker network create --opt encrypted --driver overlay my-secure-overlay
- Quand on active le chiffrage sur le réseau overlay, cela va créer un tunnel IPSEC entre les nœuds.
- Ces tunnels utilisent l’algorithme de chiffrage AES-GCM. Les noeuds manager font tourner les clés de chiffrages toutes les 12h.
- Le chiffrage du réseau n’est pas supporté sur Windows !
- Cela nécessite d'ouvrir un port supplémentaire (IPSec ESP)
¶ Créer un service en utilisant un template
On peut utiliser des templates en faisant la commande service create :
docker service create --name demoservice --hostname="{{.Node.Hostname}}-{{.Service.Name}}" nginx
Le container s’appellera donc node1-demoservice si on fait un docker exec dans le container.
$ docker exec -it demoservice.1.vmy85ssh8gkbm1myz0zy3gohh sh
# hostname
node1-demoservice
Voici les variables que l’on peut mettre :
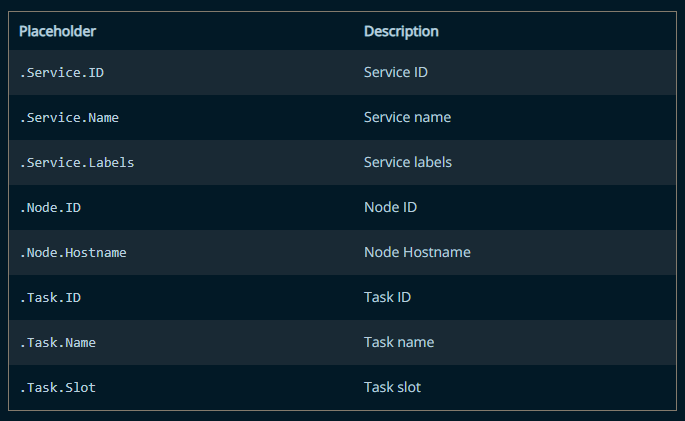
(source: Docker)
Ces variables fonctionnent pour :
- --hostname
- --mount
- --env
¶ Split-brain & Quorum :
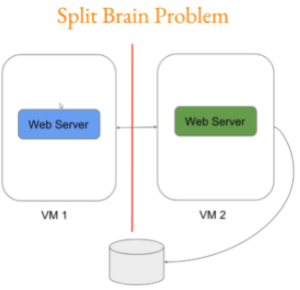
Ici les 2 web servers ne se voient plus. Ils ne peuvent donc plus communiquer entre eux et vont donc tous les deux entrer des informations en BDD :
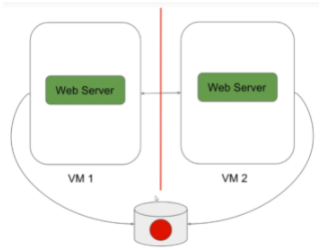
Pour éviter ce problème de split brain. Il va falloir minimum 3 serveurs pour respecter le “quorum”.
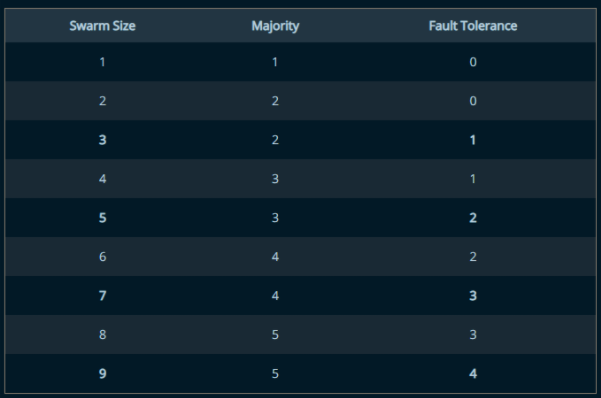
Ci-dessous le tableau taille cluster / tolérance à la panne pour éviter un split brain :
¶ Swarm manager mode HA :
Le manager a de nombreuses responsabilités dans le cluster swarm :
- Maintenir la bonne santé du cluster
- Mettre en place les services
- HTTP API endpoint
Avec l’aide du protocole RAFT, le manager maintient continuellement l'état du cluster entier et des services qui y tournent dessus.
Swarm vient avec sa propre feature de tolérance à la “faute”. On peut donc modifier cela
Docker recommande d’avoir un nombre impair de noeuds.
Un cluster avec N manager dans le cluster tolère une perte de maximum (N-1)/2 managers.
3 managers = (3-1)/2 = 1 soit maximum une perte
S’il y a trop de perte, cela va donner un split brain.
¶ Noeud manager-only avec swarm :
Par défaut, un manager fonctionne aussi comme worker. Ceci n’est pas conseillé car le manager doit faire son rôle principal uniquement : maintenir le cluster en forme !
On va donc passer le master en drain mode pour ne plus recevoir de tâches :
docker node update --availability drain <id>
Cependant, le manager continuera de faire son rôle de manager en mode "drain".
¶ Promouvoir un worker en manager
Il se peut que vous vouliez passer un noeud worker en manager. Pour se faire :
docker node promote node8
On peut aussi demote un noeud :
docker node demote node22
¶ Récupérer la perte du quorum
Comment faire si jamais on perd 1 managers sur un cluster de 2 managers ? (perte du quorum car 0 tolérance à la faute)
On passe donc les deux managers en drain mode, il nous restera 1 worker :
$ docker node update --availability drain <id>
$ docker service create --name webserver --replicas 3 nginx
$ systemctl stop docker # sur un manager
# OU
$ kill -9 `pgrep dockerd` # sur play-with-docker
On exécute une commande docker :
$ docker node ls
Error response from daemon: rpc error: code = DeadlineExceeded desc = context deadline exceeded
Ce message signifie qu'on a perdu le quorum. Le manager a perdu son homologue (manager aussi), pour éviter le split brain problem, celui-ci ne passe pas leader du cluster.
Les workers continueront à fonctionner normalement.
Pour résoudre le problème on peut :
- Redémarrer docker pour qu'il se reconnecte au cluster
- Forcer un nouveau cluster sur un noeud fonctionnel :
docker swarm init --force-new-cluster --advertise-addr 192.168.0.12
Le fait de forcer un nouveau cluster va permettre de garder la base de données de l'ancien cluster (informations sur les workers...).
On a maintenant de nouveau un cluster fonctionnel !
Le nouveau cluster sera donc crée avec un manager, le temps de trouver le problème sur le manager posant problème. Une fois le problème résolu, il faudra donc rejoindre le cluster en mode manager et rejoindre le cluster avec les autres noeuds :
docker swarm join-token manager
On va rejoindre le cluster sur les autres noeuds, mais avant, il faut quitter le cluster "corrompu" :
# Sur tous les noeuds qui ne sont pas dans le nouveau cluster
$ docker swarm leave --force
Node left the swarm.
$ docker swarm join --token SWMTKN-1-5cyj7har2a1f6t3gdqsypttmxcq2ofcsfyvb5c7pioz0l11ssk-01wqcsw2ilhex4lznmvg65y3a 192.168.0.12:2377
This node joined a swarm as a manager.
Ensuite, il va falloir enlever les noeuds obsolètes du noeud :
$ docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
a0mqibv9byudpe3eu415ymken node1 Ready Active Reachable 24.0.2
ocdc1zx308wku9ct17z07jern node1 Down Active 24.0.2
ifsymu0oozdrfp43qupkvjr8v * node2 Ready Active Leader 24.0.2
iok3cezfou4pm6x7oe9qio9a1 node3 Ready Active Reachable 24.0.2
yjrmqqrek27xwb91fryyud4te node3 Down Active 24.0.2
$ docker node rm ocdc1zx308wku9ct17z07jern
ocdc1zx308wku9ct17z07jern
$ docker node rm yjrmqqrek27xwb91fryyud4te
yjrmqqrek27xwb91fryyud4te
Le manager a pu récupérer les données des workers grâce au protocole RAFT et à la base de donnée répliquée des données internes. En regardant les services, ils sont tous présents :
$ docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
mhznd11km12x demoservice replicated 1/1 nginx:latest
lapgo9ynhu82 mywebserver replicated 2/2 nginx:latest *:8080->80/tcp
x47hi8bz7g2q webserver replicated 5/5 nginx:latest
¶ Commandes docker system
docker system | Docker Documentation
- docker system info : affiche les information du systeme
- docker system events : Récupère en temps réel les informations des containers, images… docker system events | Docker Documentation
On peut récupérer les events depuis X temps :
docker system events --since 2021-03-18
# OR
$ docker system events --since 8m
2023-08-22T14:39:45.255522518Z container destroy 2553953f3dcc65ab418d1bf80b29429ecaaffc0f56f3a8b2ea00a7e523831dce (com.docker.swarm.node.id=ocdc1zx308wku9ct17z07jern, com.docker.swarm.service.id=x47hi8bz7g2qixe6mkp949l50, com.docker.swarm.service.name=webserver, com.docker.swarm.task=, com.docker.swarm.task.id=oibwh34ftbtitz74u1h2izi2o, com.docker.swarm.task.name=webserver.1.oibwh34ftbtitz74u1h2izi2o, image=nginx:latest@sha256:104c7c5c54f2685f0f46f3be607ce60da7085da3eaa5ad22d3d9f01594295e9c, maintainer=NGINX Docker Maintainers <docker-maint@nginx.com>, name=webserver.1.oibwh34ftbtitz74u1h2izi2o)
2023-08-22T14:39:46.475560164Z network create ulhud9qe6kzlebo1h9uz09c32 (name=ingress, type=overlay)
2023-08-22T14:41:12.028428432Z network create ulhud9qe6kzlebo1h9uz09c32 (name=ingress, type=overlay)
2023-08-22T14:44:21.483854297Z node remove ocdc1zx308wku9ct17z07jern (name=node1)
2023-08-22T14:44:24.573564153Z node remove yjrmqqrek27xwb91fryyud4te (name=node3)
Pour voir en détail l’utilisation du disque par docker on peut faire la commande suivante :
docker system df
On peut aussi supprimer les infos non utilisées (volumes, network, images...) :
docker system prune
docker image prune
docker volume prune