¶ Gestion des Secrets Kubernetes
Nous allons créer un pod avec 2 secrets :
root@cks-master:~$ k create secret generic secret1 --from-literal user=admin
secret/secret1 created
root@cks-master:~$ k create secret generic secret2 --from-literal pass=12345678
secret/secret2 created
Puis créer un pod avec secret1 en file, secret2 en ENV :
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod
name: pod
spec:
containers:
- image: nginx
name: pod
resources: {}
env:
- name: PASSWORD
valueFrom:
secretKeyRef:
name: secret2
key: pass
volumeMounts:
- name: secret1
mountPath: "/etc/secret1"
readOnly: true
volumes:
- name: secret1
secret:
secretName: secret1
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
On peut vérifier que tout est ok :
Antoine@cks-master:~$ k exec pod -- env | grep PASS
PASSWORD=12345678
Antoine@cks-master:~$ k exec pod -- mount | grep secret1
tmpfs on /etc/secret1 type tmpfs (ro,relatime,size=3920272k)
Antoine@cks-master:~$ k exec pod -- cat /etc/secret1/user
admin
¶ Hack du secret via le CRI
Les 2 secrets que l'on a crée ci-dessus sont stockés dans ETCD. Cependant si un hacker parvient à avoir un compte qui a accès au CRI (containerd dans notre cas), il est très facile pour lui de récupérer les informations des secrets :
# Tourne sur le worker :
Antoine@cks-master:~$ k get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod 1/1 Running 0 7m50s 10.44.0.1 cks-worker <none> <none>
# Sur le worker :
root@cks-worker:~$ crictl ps
CONTAINER IMAGE CREATED STATE NAME ATTEMPT POD ID
bc55c2c4c8299 55f4b40fe486a 8 minutes ago Running pod 0 09922eddeabdc
bcdf15198fe06 3f3a6119b12a5 10 days ago Running controller 3 45304e193693a
...
root@cks-worker:~$ crictl inspect bc55c2c4c8299
{
"status": {
...
"env": [
"PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin",
"HOSTNAME=pod",
"NGINX_VERSION=1.23.0",
"NJS_VERSION=0.7.5",
"PKG_RELEASE=1~bullseye",
"PASSWORD=12345678",
"KUBERNETES_PORT_443_TCP=tcp://10.96.0.1:443",
"KUBERNETES_PORT_443_TCP_PROTO=tcp",
"KUBERNETES_PORT_443_TCP_PORT=443",
"KUBERNETES_PORT_443_TCP_ADDR=10.96.0.1",
"KUBERNETES_SERVICE_HOST=10.96.0.1",
"KUBERNETES_SERVICE_PORT=443",
"KUBERNETES_SERVICE_PORT_HTTPS=443",
"KUBERNETES_PORT=tcp://10.96.0.1:443"
],
...
{
"destination": "/etc/secret1",
"type": "bind",
"source": "/var/lib/kubelet/pods/6af0598d-6beb-4090-9959-1e13442279e0/volumes/kubernetes.io~secret/secret1",
"options": [
"rbind",
"rprivate",
"ro"
]
}
...
root@cks-worker:~$ cat /var/lib/kubelet/pods/6af0598d-6beb-4090-9959-1e13442279e0/volumes/kubernetes.io~secret/secret1/user
admin
On peut aussi se baser sur le PID du container :
...
"info": {
"sandboxID": "09922eddeabdc9d0acf13779b7e4d94df7deb0f44e6175292ef2c37a9f1a8211",
"pid": 31251,
"removing": false,
"snapshotKey": "bc55c2c4c8299144cda99657b022f22209d072cf33ba2a7399ab7af9deb72469",
"snapshotter": "overlayfs",
...
root@cks-worker:~$ ls /proc/31251/root
bin boot dev docker-entrypoint.d docker-entrypoint.sh etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
root@cks-worker:~$ cat /proc/31251/root/etc/secret1/user
admin
Cela ne représente pas une grosse faille étant donné que si quelqu'un a cet accès... Il est sûrement déjà bien trop tard.
¶ Hack du secret via ETCD
Il est possible via ETCD de récupérer les secrets :
# On vérifie que ETCD tourne bien :
root@cks-master:~$ ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/ca.crt endpoint health
127.0.0.1:2379 is healthy: successfully committed proposal: took = 14.944866ms
# On récupère le secret1 :
root@cks-master:~$ ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/ca.crt get /registry/secrets/default/secret1
/registry/secrets/default/secret1
k8s
...
+{"f:data":{".":{},"f:user":{}},"f:type":{}}B
useradminOpaque
# On récupère le secret2 :
root@cks-master:~$ ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/ca.crt get /registry/secrets/default/secret2
/registry/secrets/default/secret2
...
+{"f:data":{".":{},"f:pass":{}},"f:type":{}}B
pass12345678Opaque"
¶ Chiffrer ETCD
Heureusement nous pouvons chiffrer ETCD.
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- identity: {} # No encryption
- aesgcm: # AES-GCM with random nonce
keys:
- name: key1
secret: c2VjcmV0IGlzIHNlY3VyZQ==
- name: key2
secret: dGhpcyBpcyBwYXNzd29yZA==
- aescbc: # AES-CBC with PKCS#7 padding
keys:
- name: key1
secret: c2VjcmV0IGlzIHNlY3VyZQ==
- name: key2
secret: dGhpcyBpcyBwYXNzd29yZA==
- secretbox: # XSalsa20 and Poly1305
keys:
- name: key1
secret: YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXoxMjM0NTY=
Voici en pratique ce que nous devons faire pour chiffrer ETCD :
- Créer le dossier
etcddans/etc/kubernetes - Ajouter le fichier
ec.yamlavec les valeurs suivantes :
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- aescbc:
keys:
- name: key1
# entrer un secret de 16 24 ou 32 caractères
secret: cGFzc3dvcmRwYXNzd29yZA== # echo -n passwordpassword | base64
- identity: {} # Très important pour continuer de voir les secrets (système ou non) non chiffrés !
Seulement un secret de 16, 24 ou 32 caractères, kube-apiserver ne démarrera pas sinon (voir log /var/logs/pods/kube-system_kube-apiserver...)
- Modifier la configuration de
kupe-apiserver.yamlen ajoutant le paramètre--encryption-provider-config=/etc/kubernetes/etcd/ec.yamlet en ajoutant le volume :
...
volumeMounts:
- mountPath: /etc/kubernetes/etcd
name: etcd
readOnly: true
...
volumes:
- hostPath:
path: /etc/kubernetes/etcd
type: DirectoryOrCreate
name: etcd
...
- Une fois
kube-apiserverredémarré, les anciens secrets ne sont pas chiffrés mais sont visibles (grace àidentity: {}) :
root@cks-master:~$ ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/ca.crt get /registry/secrets/default/secret2
/registry/secrets/default/secret2
k8s
v1Secret�
�
secret2default"*$c0e7c2d3-8db6-4190-9898-5d5c0c3c74312ƽ��z�a
kubectl-createUpdatevƽ��FieldsV1:-
+{"f:data":{".":{},"f:pass":{}},"f:type":{}}B
pass12345678Opaque"
- En créant un secret :
root@cks-master:/home/Antoine$ k create secret generic secure --from-literal private=123456789
secret/secure created
root@cks-master:/home/Antoine$ ETCDCTL_API=3 etcdctl --cert /etc/kubernetes/pki/apiserver-etcd-client.crt --key /etc/kubernetes/pki/apiserver-etcd-client.key --cacert /etc/kubernetes/pki/etcd/ca.crt get /registry/secrets/default/secure
/registry/secrets/default/secure
k8s:enc:aescbc:v1:key1:@pq?q6꽟!��3
�M��X.�o�ϻ?�h1)�������¾�$����"��]�*�'G���[��3i�&"�w��)��(��1r ���Nݗ�
)S���P�6/a�q˞֯j����H
M5?Zo�pא#��tj��
a�re)�S t�l�\K4��!���>q��^{~��J1��8(T���[�Ǐ[2Չ�mK=��l8�H�������
����1�����F��C���0
,��[bj��`|]��
root@cks-master:/home/Antoine$ k get secret secure -oyaml
apiVersion: v1
data:
private: MTIzNDU2Nzg5
On voit donc que les nouveaux secrets ne sont plus accessible via ETCD, cependant bien accessible via kubectl.
- Pour chiffrer un secret existant, il faut le delete et le recréer (y compris le
default-token-6gtjb!) :
root@cks-master:/home/Antoine$ k get secret -A -oyaml | kubectl replace -f -
...
secret/secure-ingress replaced
secret/default-token-t6qw7 replaced
secret/ingress-nginx-admission replaced
...
Une fois avoir effectué cela, on peut maintenant enlever la ligne identity: {} du fichier ec.yaml car nous n'avons plus de secret en clair dans notre cluster.
En production, mieux vaut utiliser le provider KMS afin d'utiliser un serveur externe de gestion de clés.
¶ CRI Sandbox
Ce n'est pas parce que ça tourne dans un container que c'est plus sécurisé. Nous allons le voir dans cette partie.
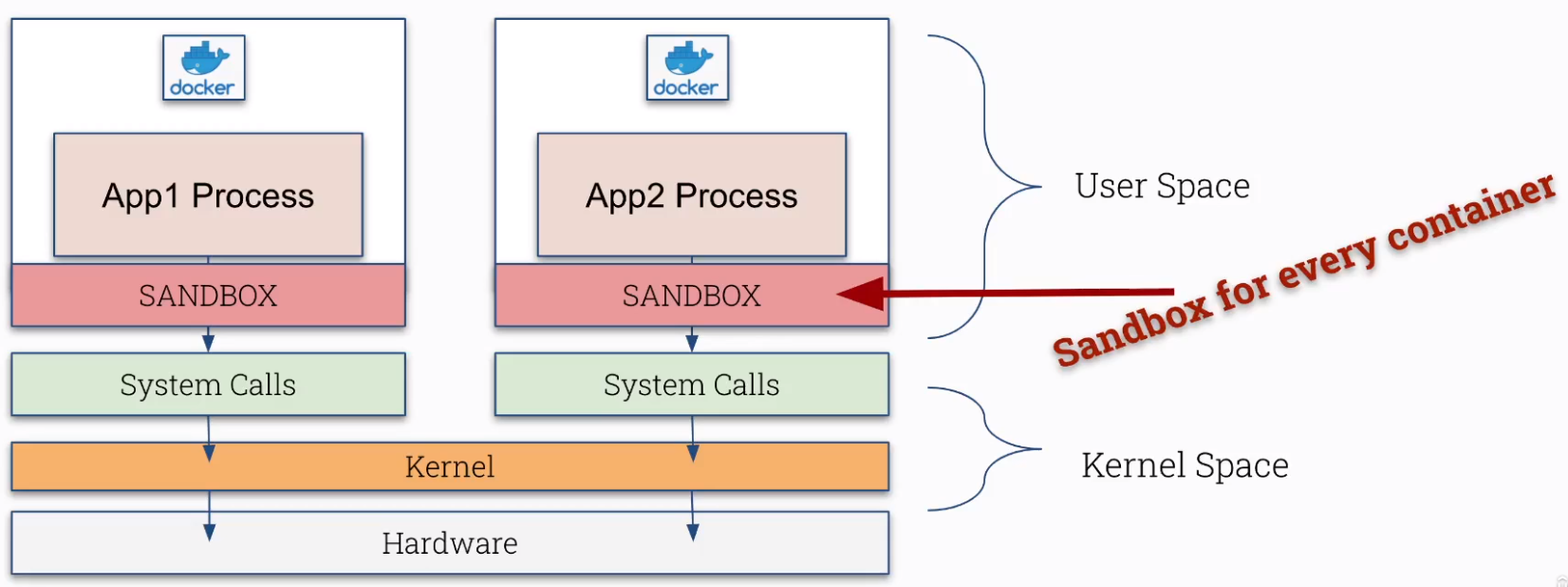
Cependant Sandbox a un coût :
- Utilise plus de ressources
- Peut-être mieux pour des petits containers
- Non adaptés pour des containers avec beaucoup de d'appels systèmes (syscall)
- Pas d'accès direct au hardware
¶ Conteneur --> Kernel Linux
Nous allons contacter le kernel linux depuis un container (whouaaa, mais en fait il n'y a rien de fou) :
root@cks-master:~$ k exec pod -it -- bash
root@pod:/# uname -r
5.4.0-1080-gcp
root@pod:/# exit
exit
root@cks-master:~$ uname -r
5.4.0-1080-gcp
On a ici effectué un appel système (syscall) uname et nous voyons que nous sommes sur le même kernel, qu'on soit dans le container ou en dehors.
¶ Création d'un sandbox
Il existe différent type de sandbox (Katacontainers, gvisor...). Afin de faire tourner un sandbox nous devons créer un RuntimeClasses qui permet de faire tourner plusieur CRI dans un seul cluster.
Voici la configuration pour lancer le CRI runsc (gvisor) avec une RuntimeClass :
apiVersion: node.k8s.io/v1
kind: RuntimeClass
metadata:
name: gvisor
handler: runsc
Une fois appliquée :
root@cks-master:~# k apply -f rc.yaml
runtimeclass.node.k8s.io/gvisor created
root@cks-master:~# k get runtimeclass
NAME HANDLER AGE
gvisor runsc 5s
Nous allons maintenant lancer un pod sur la RuntimeClass créée ci-dessus :
apiVersion: v1
kind: Pod
metadata:
labels:
run: gvisor
name: gvisor
spec:
runtimeClassName: gvisor
containers:
- image: nginx
name: gvisor
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
Dans le cadre du CKS, runsc existe de base sur le noeud. Nous ne ferons pas l'installation.
Cependant, une fois le pod lancé, si nous refaisons la commande uname -r le kernel n'est pas le même que le noeud sur lequel il tourne.
¶ Security Contexts, Non-root, Privilege escalation
¶ Security Contexts
La plupart du temps, lorsque l'on lance un pod et que l'on s'y attache nous sommes souvent avec l'utilisateur root. Cela peut poser de gros problèmes de sécurité.
Antoine@cks-master:~$ k run pod --image=busybox --command -- sh -c 'sleep 3600'
Antoine@cks-master:~$ k exec -it pod -- sh
/ $ id
uid=0(root) gid=0(root) groups=10(wheel)
Nous allons modifier cela :
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod
name: pod
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- command:
- sh
- -c
- sleep 3600
image: busybox
name: pod
resources: {}
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
En testant :
Antoine@cks-master:~$ k replace -f pod.yaml --force
pod "pod" deleted
pod/pod replaced
Antoine@cks-master:~$ k exec -it pod -- sh
/ $ id
uid=1000 gid=3000 groups=2000
/ $ touch test
touch: test: Permission denied
/ $ cd tmp/
/tmp $ touch test
/tmp $ ls -l
total 0
-rw-r--r-- 1 1000 3000 0 Jul 1 21:19 test
¶ Container non-root
On peut forcer un container à se lancer uniquement si l'utilisateur du processus principal est non-root :
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod
name: pod
spec:
securityContext:
runAsUser: 1000
runAsGroup: 3000
fsGroup: 2000
containers:
- command:
- sh
- -c
- sleep 3600
image: busybox
name: pod
resources: {}
securityContext:
runAsNonRoot: true # Si l'uid = 0, alors quitte le container en erreur
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
Dans ce cas, RAS le pod se lance bien. Cependant si nous enlevons la securityContext de spec :
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod
name: pod
spec:
containers:
- command:
- sh
- -c
- sleep 3600
image: busybox
name: pod
resources: {}
securityContext:
runAsNonRoot: true # Si l'uid = 0, alors quitte le container en erreur
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
On aura l'erreur suivante :
Antoine@cks-master:~$ k get pod
NAME READY STATUS RESTARTS AGE
pod 0/1 CreateContainerConfigError 0 23s
Antoine@cks-master:~$ k describe pod pod
...
Events:
Warning Failed 11s (x3 over 28s) kubelet Error: container has runAsNonRoot and image will run as root (pod: "pod_default(3653cac6-a4f9-45de-81cf-ba706271e738)", container: pod)
¶ Privileged container
privileged signifie que l'utilisateur root (uid=0) du container sera mappé au même utilisateur root de l'hôte. Par défaut, privileged n'est pas activé. Pour l'activer :
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod
name: pod
spec:
containers:
- command:
- sh
- -c
- sleep 3600
image: busybox
name: pod
resources: {}
securityContext:
privileged: true
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
¶ Privilege escalation
Cela permet de contrôler si oui ou non un process peut avoir plus de droits que son process parent. Par défaut, Kubernetes autorise ce privilege escalation.
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: pod
name: pod
spec:
containers:
- command:
- sh
- -c
- sleep 3600
image: busybox
name: pod
resources: {}
securityContext:
allowPrivilegeEscalation: false
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
Nous vérifions ensuite notre paramètre :
Antoine@cks-master:~$ k exec -it pod -- sh
/ # cat /proc/1/status
...
NoNewPrivs: 1
...
Le paramètre a bien été désactivé.
¶ PodSecurityPolicy
Déprécié en 1.21, supprimé en v1.25. Préférer les Pod Security Admission
Objet kubernetes non-namespaced qui permet d'appliquer des règles de sécurité aux pods du cluster.
PodSecurityPolicy n'est pas activé par défaut, il faut donc l'activer dans kube-apiserver.yaml :
spec:
containers:
- command:
- kube-apiserver
...
- --enable-admission-plugins=NodeRestriction,PodSecurityPolicy
Voici un exemple de fichier PodSecurityPolicy :
apiVersion: policy/v1beta1
kind: PodSecurityPolicy
metadata:
name: example
spec:
allowPrivilegeEscalation: false
privileged: false
seLinux:
rule: RunAsAny
supplementalGroups:
rule: RunAsAny
runAsUser:
rule: RunAsAny
fsGroup:
rule: RunAsAny
volumes:
- '*'
¶ mTLS / Mutual TLS
mTLS sert à l'authentification mutuelle, 2 services s'authentifient en même temps.
Par défaut la communication Pod à Pod n'est pas chiffré, mTLS va venir chiffrer tout le traffic.
La mise en place de mTLS entre pod se fait via un sidecar :
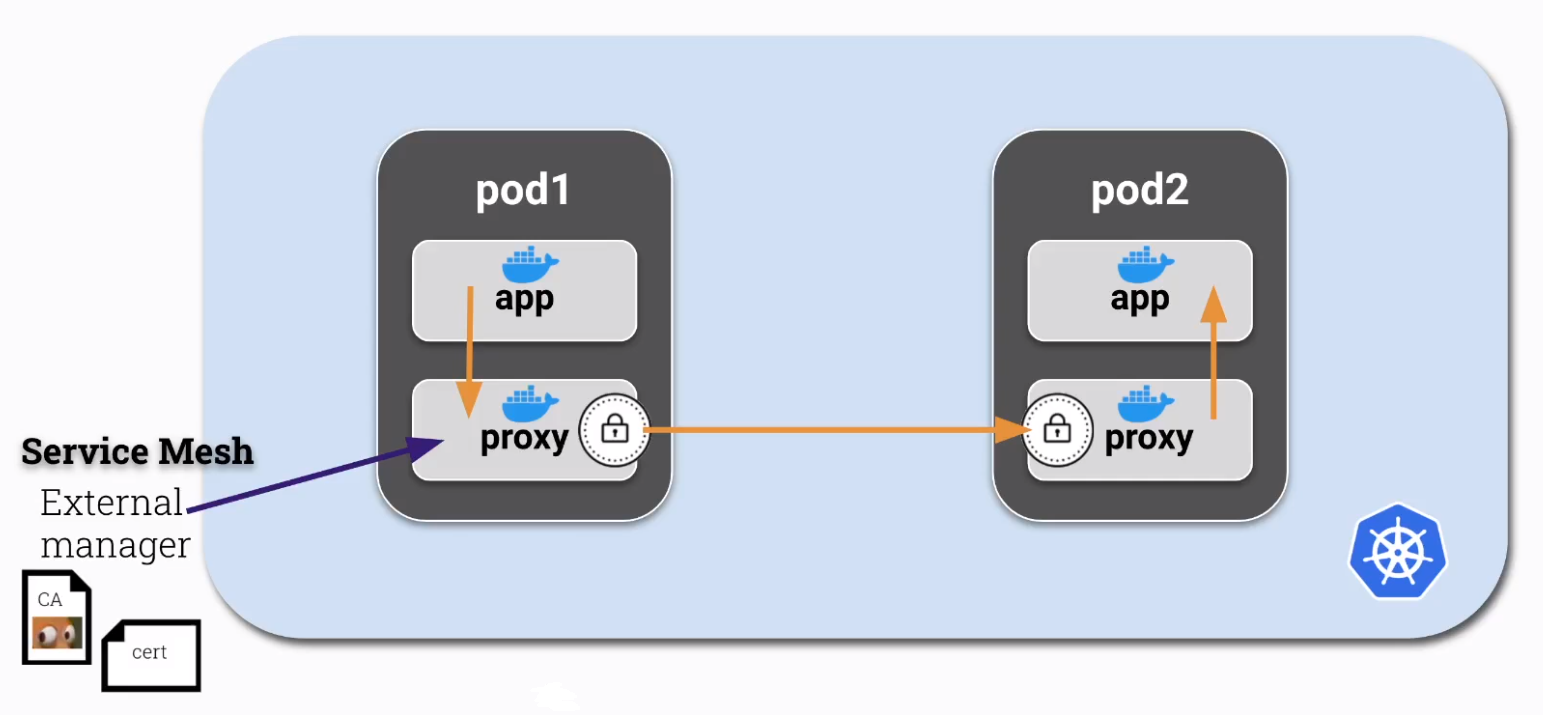
Pour se faire il faut :
- Créer un sidecar avec la capability
NET_ADMIN
$ k run app --image=bash --command -oyaml --dry-run=client > mtls.yaml -- sh -c 'ping google.com'
# Puis modifier le fichier
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
labels:
run: app
name: app
spec:
containers:
- command:
- sh
- -c
- ping google.com
image: bash
name: app
resources: {}
- name: proxy
image: ubuntu
command:
- sh
- -c
- 'apt-get update && apt-get install iptables -y && iptables -L && sleep 1d'
securityContext:
capabilities:
add: ["NET_ADMIN"]
dnsPolicy: ClusterFirst
restartPolicy: Always
status: {}
A l'heure actuelle, cette partie est très floue côté CNCF et je ne sais pas ce qui peut-être demandé sur cette partie...